
我们的任务是训练一个 GAN 用于生成二次元头像。主要参考了李宏毅老师的 GAN 教程 ,数据集来源于李宏毅老师的 作业 3。
生成器是输入 100 维度的 latent vector,通过转置卷积和最后的全连接层,生成 64×64 的图像。
先简要说一下训练过程中遇到的问题。
- 迭代若干次之后,生成图片为纯黑色。
降低学习率可以避免这种情况。 - D 太强势,对真图直接标为 1.0,对假图直接标为 0.0,梯度很小,导致 G 学不到多少东西。
网上有人说「给标签加噪音」,有人说「改 k 值」。我这边把 k 值调得很低,可以缓解。另外降低了 D 的学习率,也有一些效果。 - D 严重欠拟合,所有的图片都给出同样的分数。
我是调整网络结构之后缓解了这个情况。降低学习率似乎也有用。
第一遍写代码,是自己搞的模型。生成器通过转置卷积层与卷积层的组合来造图片;判别器是 CNN,但是没有池化层(为了尽量少丢失信息),而是采用了 stride = 2 的卷积层来减少特征。代码如下:
import torch
import torch.nn as nn
import torchvision
import os
import numpy as np
import PIL.Image as Image
import itertools
import matplotlib.pyplot as pltbatchsize = 32
images_dataset = torchvision.datasets.ImageFolder(
os.path.join('data'),
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Resize(64)]))
realimg_loader = torch.utils.data.DataLoader(
images_dataset,
batch_size=batchsize,
shuffle=True)
realimg_iter = iter(realimg_loader)
sample_x, _ = next(iter(realimg_loader))plt.figure(figsize=(10, 10))
plt.imshow(torchvision.utils.make_grid(sample_x).numpy().transpose((1, 2, 0)))
接下来定义生成器:先经过一个全连接层,再用转置卷积层、卷积层来生成更大的图片;最后输出 64×64 的图。激活函数用 relu,输出层用 tanh。这里我在输出时规范化到 $[0, 1]$ 之间,之后实践证明这不是很好的方案。应该不改这个 tanh,而是把真实图像规范化到 $[-1, 1]$ 内。
class Gen(nn.Module):
def __init__(self):
super().__init__()
self.fc = nn.Linear(100, 32*16*16)
self.upsamp1 = nn.ConvTranspose2d(32, 128, 4, stride=2)
self.conv1 = nn.Conv2d(128, 128, 4)
self.upsamp2 = nn.ConvTranspose2d(128, 128, 4, stride=2)
self.conv2 = nn.Conv2d(128, 64, 4)
self.conv3 = nn.Conv2d(64, 3, 4, padding=3)
def forward(self, x):
x = self.fc(x)
x = torch.relu(x)
x = x.view(-1, 32, 16, 16)
x = self.upsamp1(x)
x = self.conv1(x)
x = torch.relu(x)
x = self.upsamp2(x)
x = self.conv2(x)
x = torch.relu(x)
x = self.conv3(x)
x = torch.tanh(x)
return x / 2 + .5判别器,一个简单的 CNN,没有池化。
class Dis(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 32, 4, stride=2)
self.conv2 = nn.Conv2d(32, 64, 4, stride=2)
self.conv3 = nn.Conv2d(64, 128, 4, stride=2)
self.conv4 = nn.Conv2d(128, 256, 4, stride=2)
self.fc = nn.Linear(256 * 2 * 2, 1)
def forward(self, x):
x = torch.relu(self.conv1(x))
x = torch.relu(self.conv2(x))
x = torch.relu(self.conv3(x))
x = torch.relu(self.conv4(x))
x = x.view(-1, 256 * 2 * 2)
x = torch.sigmoid(self.fc(x))
return x采用 Adam 优化器:
gen = Gen()
optim_gen = torch.optim.Adam(gen.parameters(), lr=0.0002, betas=(.5, .999))
dis = Dis()
optim_dis = torch.optim.Adam(dis.parameters(), lr=0.0002, betas=(.5, .999))训练这两个网络的代码:
def train_dis(cnt, gen, dis):
gen.requires_grad_(False)
dis.requires_grad_(True)
for x in range(cnt):
fake_img = gen(torch.randn([batchsize, 100]))
real_img, _ = next(realimg_iter)
optim_dis.zero_grad()
loss = - (torch.sum(torch.log(1 - dis(fake_img))) + torch.sum(torch.log(dis(real_img)))) / batchsize
# print(f'train dis, round {x} loss={loss.item()}')
loss.backward()
optim_dis.step()
# with torch.no_grad():
# correct_real = sum(dis(real_img) > .5)
# correct_fake = sum(dis(fake_img) < .5)
# print(f'correct_real: {correct_real.item()} / {batchsize}, correct_fake: {correct_fake.item()} / {batchsize}')
def train_gen(cnt, gen, dis):
gen.requires_grad_(True)
dis.requires_grad_(False)
for x in range(cnt):
fake_img = gen(torch.randn([batchsize, 100]))
optim_gen.zero_grad()
loss = - torch.sum(torch.log(dis(fake_img))) / batchsize
# print(f'train gen, round {x} loss={loss.item()}')
loss.backward()
optim_gen.step()
# with torch.no_grad():
# success_cnt = sum(dis(fake_img) > .5)
# print(f'success: {success_cnt.item()} / {batchsize}')
接下来开始迭代。注意 GAN 非常不稳定,随时可能过拟合、模式坍塌,需要回档调参数继续训练。所以模型要定期存 checkpoint。
for x in range(2000):
print(f'> round {x}\n')
realimg_iter = itertools.cycle(realimg_loader)
for c in range(10):
train_dis(5, gen, dis)
train_gen(1, gen, dis)
with torch.no_grad():
test = gen(torch.randn([batchsize, 100]))
show_img(test[0])
if x % 100 == 99:
torch.save({
'gen': gen.state_dict(),
'optim_gen': optim_gen.state_dict(),
'dis': dis.state_dict(),
'optim_dis': optim_dis.state_dict()
}, f'checkpoint0227-{x}.pth')几百次迭代之后,产出如下:
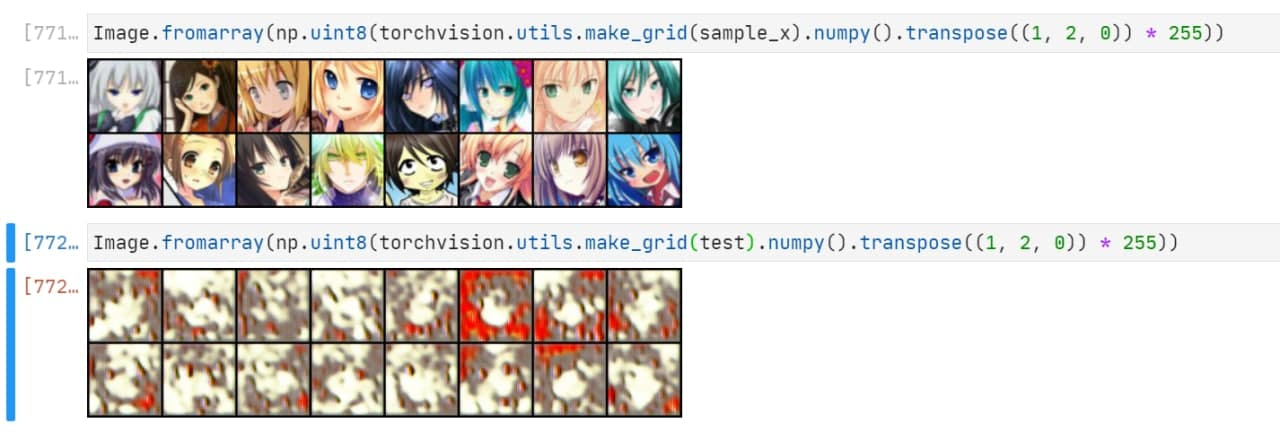
再进行一些迭代之后结果如下。注意到已经产生了模式坍塌。

调整参数之后训练几千轮,最终结果如下:
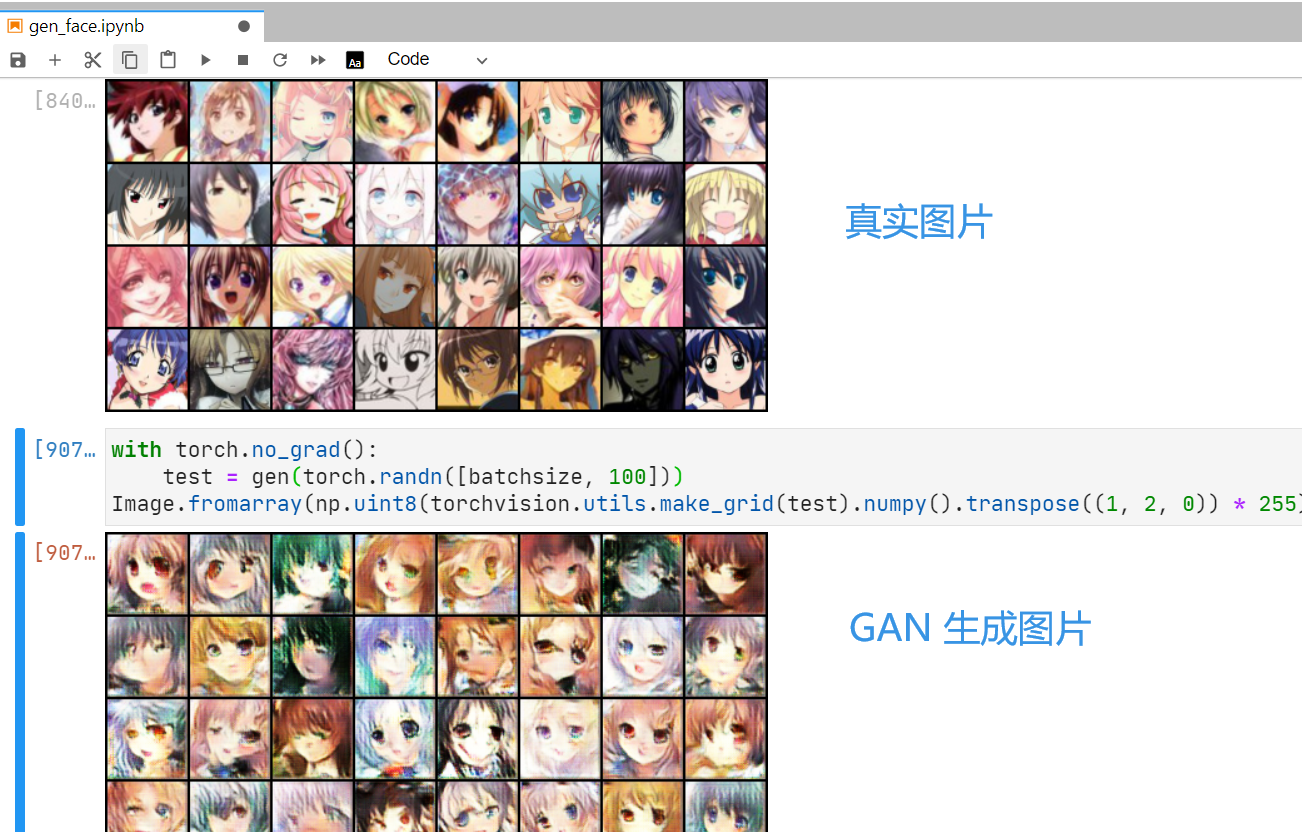
总之就是非常抽象。挑了几张好看一点的,与诸君共赏:









看起来确实像个人,反正比我画得好。
3 月 1 日,我用 DCGAN 重写了一遍。主要参考了 PyTorch 的官方教程。

DCGAN 引入了 BatchNorm 来加快收敛、改善效果,另外取消了全连接层,使得生成器和判别器都是全卷积网络。
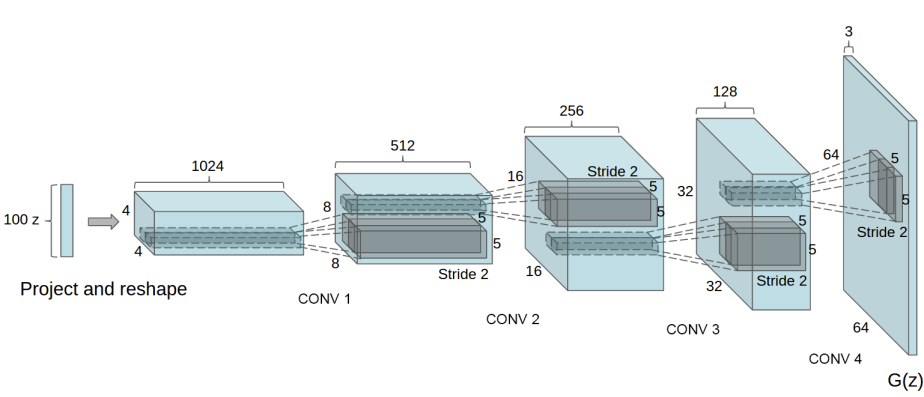
import torch
import torch.nn as nn
import torchvision
import os
import numpy as np
import PIL.Image as Image
import itertools
import matplotlib.pyplot as pltbatchsize = 128
learning_rate_gen = 0.0002
learning_rate_dis = 0.0002
beta1 = 0.5
dim_latent_vector = 100
num_gen_feature_map = 64
num_dis_feature_map = 64
num_gen_output_channel = 3
k = 1images_dataset = torchvision.datasets.ImageFolder(
os.path.join('data'),
transform=torchvision.transforms.Compose([
torchvision.transforms.Resize(64),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([.5, .5, .5], [.5, .5, .5])]))
realimg_loader = torch.utils.data.DataLoader(
images_dataset,
batch_size=batchsize,
shuffle=True)
images_dataset现在我们的图像,无论是真实的图,还是生成的图,都是 $[-1, 1]$ 范围内的了。写一点用于输出图像的辅助函数:
realimg_iter = iter(realimg_loader)
sample_x, _ = next(iter(realimg_loader))
data_to_image = torchvision.transforms.Compose([
torchvision.transforms.Normalize([-1, -1, -1], [2, 2, 2]),
torchvision.transforms.ToPILImage()])
def show_img(x):
plt.imshow(data_to_image(x))
def show_grid(x, title=None):
plt.figure(figsize=(10, 10))
plt.title(title)
plt.imshow(data_to_image(torchvision.utils.make_grid(x)))
plt.show()
show_grid(sample_x[:32], 'training dataset');
这一次网络很大,我们采用 GPU 来训练:
device = torch.device("cuda:0")
device
# device(type='cuda', index=0)根据 paper,需要把网络的初始参数调成 $N(0, 0.02)$,我们写一个函数,用于接下来初始化网络。
def set_layer_init_weight(layer):
if 'Conv' in layer.__class__.__name__:
nn.init.normal_(layer.weight.data, 0, 0.02)
elif 'BatchNorm' in layer.__class__.__name__:
nn.init.normal_(layer.weight.data, 1, 0.02)
nn.init.constant_(layer.bias.data, 0)定义生成器和判别器:
class Gen(nn.Module):
def __init__(self):
super().__init__()
self.main = nn.Sequential(
nn.ConvTranspose2d(dim_latent_vector, num_gen_feature_map * 8, 4, bias=False),
nn.BatchNorm2d(num_gen_feature_map * 8),
nn.ReLU(True),
nn.ConvTranspose2d(num_gen_feature_map * 8, num_gen_feature_map * 4, 4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(num_gen_feature_map * 4),
nn.ReLU(True),
nn.ConvTranspose2d(num_gen_feature_map * 4, num_gen_feature_map * 2, 4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(num_gen_feature_map * 2),
nn.ReLU(True),
nn.ConvTranspose2d(num_gen_feature_map * 2, num_gen_feature_map, 4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(num_gen_feature_map),
nn.ReLU(True),
nn.ConvTranspose2d(num_gen_feature_map, num_gen_output_channel, 4, stride=2, padding=1, bias=False),
nn.Tanh()
)
def forward(self, x):
return self.main(x)
net_gen = Gen().to(device)
net_gen.apply(set_layer_init_weight)
net_gen
class Dis(nn.Module):
def __init__(self):
super().__init__()
self.main = nn.Sequential(
nn.Conv2d(num_gen_output_channel, num_dis_feature_map, 4, stride=2, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(num_dis_feature_map, num_dis_feature_map * 2, 4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(num_dis_feature_map * 2),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(num_dis_feature_map * 2, num_dis_feature_map * 4, 4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(num_dis_feature_map * 4),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(num_dis_feature_map * 4, num_dis_feature_map * 8, 4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(num_dis_feature_map * 8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(num_dis_feature_map * 8, 1, 4, bias=False),
nn.Sigmoid()
)
def forward(self, x):
return self.main(x)
net_dis = Dis().to(device)
net_dis.apply(set_layer_init_weight)
net_dis
定义损失函数和优化器:
criterion = nn.BCELoss()
fixed_noise = torch.randn(64, dim_latent_vector, 1, 1, device=device)
label_real = 1.0
label_fake = 0.0
optim_gen = torch.optim.Adam(net_gen.parameters(), lr=learning_rate_gen, betas=(beta1, 0.999))
optim_dis = torch.optim.Adam(net_dis.parameters(), lr=learning_rate_dis, betas=(beta1, 0.999))训练:
loss_gen = []
loss_dis = []
iter_count = 0
def train_epoch():
global iter_count
for i, real_data in enumerate(realimg_loader):
# 训练 dis,maximize log(D(x)) + log(1 - D(G(z)))
for x in range(k):
net_dis.zero_grad()
real_data_gpu = real_data[0].to(device)
this_data_size = real_data[0].size(0)
label = torch.full((this_data_size, ), label_real, device=device)
output = net_dis(real_data_gpu).view(-1)
err_dis_real = criterion(output, label)
err_dis_real.backward()
avg_real_score = output.mean().item()
noise = torch.randn(this_data_size, dim_latent_vector, 1, 1, device=device)
fake_data_gpu = net_gen(noise)
label.fill_(label_fake)
output = net_dis(fake_data_gpu.detach()).view(-1)
err_dis_fake = criterion(output, label)
err_dis_fake.backward()
avg_fake_score = output.mean().item()
err_dis = err_dis_real + err_dis_fake
optim_dis.step()
# 训练 gen, maximize log(D(G(z)))
net_gen.zero_grad()
label.fill_(label_real)
output = net_dis(fake_data_gpu).view(-1) # 复用刚刚训练 dis 时生成的假图
err_gen = criterion(output, label)
err_gen.backward()
avg_fake_score_after = output.mean().item() # dis 训练一次之后,再判断假图的打分
optim_gen.step()
if i % 50 == 0:
print(f'iter {iter_count} [{i}/{len(realimg_loader)}] dis loss: {err_dis.item()} gen loss: {err_gen.item()}')
print(f'D(real): {avg_real_score} D(fake): {avg_fake_score} -> {avg_fake_score_after}')
loss_gen.append(err_gen.item())
loss_dis.append(err_dis.item())
if i % 50 == 0:
with torch.no_grad():
new_fake_img = net_gen(fixed_noise).detach().cpu()
show_grid(new_fake_img[:32])
iter_count += 1于是就写完了。来看一下效果:


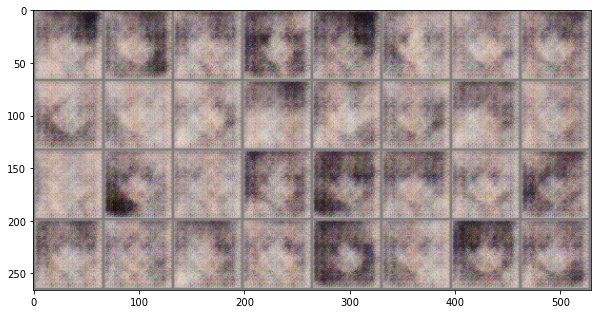
可见 DCGAN 比我们之前的模型生成能力强很多。1000 次迭代之后是下面的样子:

48000 次迭代之后,成品如下:

当然仍然很不真实,但比我们旧模型还是稍好一些。我们旧模型有类似抽象画的纹理,DCGAN 生成的图没有这种纹理。选了一些 DCGAN 产品,奇图共赏:



