

笔者近期在学习 Spring Boot。一方面是为了看懂别人的代码,另一方面,近几年国内 CTF 竞赛有从 PHP 向 Java 转向的趋势,现代 web 选手必然要学习 Spring 套件;笔者近期计划重构 Blueberry 竞赛平台,也打算用 Spring 实现。
马克吐温有个著名的笑话:戒烟是最容易的事情,我已经戒了一百次了。对笔者而言,学习 Spring 也是最容易的事情,笔者已经学了三次了。总结笔者之前学习 Spring 失败的原因,大致是习惯了其他语言的编程范式,对 Java 的社区普遍实践缺乏感觉;加之社区中的教程普遍鸡毛蒜皮,容易把人带进迷宫里——以这篇教程为例,第一章就讲配置文件、环境变量、日志、MVC、各种 starter,令人找不着北。笔者之所以在无数 Spring 教程之外再新写一篇教程,是为了帮助跟笔者一样的、已经熟悉其他编程语言的读者,把陡峭的学习曲线拉平,从而以一个下午的时间快速入门 Spring Boot。
对 Python 程序员来说,在学习 Spring 之前,首先需要转变编程思维,把自己变成 Java 程序员的样子。笔者不是说 Java 实践比 Python 实践优秀;Java 实践是语言本身的掣肘与社区潮流共同作用,在漫长的历史中形成的一套妥协性的方案。例如,Java 是彻底的 OOP 语言,再简单的函数也要依托在 class 上,这影响了很多设计。笔者认为,在初学 Spring 时,最值得注意的范式就是“单例服务员”。
单例服务员
假设我们想实现一个函数,查询广州到哈尔滨的所有机票和火车价格,从中返回最便宜的。Python 用户马上会写出下面的代码:
def get_train_price():
return httpx.get('https://trip.example.com/api/train/today').json()
def get_flight_price():
return httpx.get('https://trip.example.com/api/flight/today').json()
def get_cheapest_price():
return min(get_train_price() + get_flight_price())编写 Python 时,我们会无意间减少抽象层次,获得更通透的控制权。然而,如果按照 Spring 的思维,则代码应该写成这样:
class TrainPriceService:
def get_price(self):
return httpx.get('https://trip.example.com/api/train/today').json()
class FlightPriceService:
def get_price(self):
return httpx.get('https://trip.example.com/api/flight/today').json()
class CheapestPriceService:
# 注意这个构造函数,它依赖一个 TrainPriceService 和一个 FlightPriceService
def __init__(self, train_service, flight_service):
self.train_service = train_service
self.flight_service = flight_service
def get_cheapest_price(self):
return min(self.train_service.get_price() + self.flight_service.get_price())并且,在运行时,我们会构造一个 TrainPriceService 单例和一个 FlightPriceService 单例,然后利用这两个单例来构造 CheapestPriceService 单例。最后,用户访问这个单例的 get_cheapest_price() 方法,以获取最低价格。
读者可以看到,在 Spring 风格的代码中,我们是在与 Service 单例频繁交互。可以把 Service 单例理解为“服务员”——我们向服务员甲询问某事,甲回头向乙、丙询问原始数据,整理成答案再回复我们。Spring 的大厅里存在着若干服务员,每个服务员都可能依赖于其他服务员。在本例中,负责统计最低价格的服务员依赖于火车服务员和航班服务员,越靠近用户的服务员抽象层级越高,越远离用户的服务员越接近原始数据。
学会在业务系统中想象出一个个服务员,笔者认为,是从 Python 思维转向 Spring 思维的关键。举另一个例子,在 Flask 编程时,要实现博客文章的读取和编辑,我们经常会写这样的代码:
@app.get('/posts/<id>')
def read_post(id):
with get_db() as db:
return db.execute('SELECT * FROM post WHERE id = %s', [id]).fetchone()
@app.post('/posts/<id>/edit')
def edit_post(id):
with get_db() as db:
db.execute('UPDATE post SET content = %s WHERE id = %s', [request.form['content'], id])
return 'ok'
但在 Spring 风格中,我们有“文章数据库管理者”这个服务员,代码会变成:
class BlogPostService:
# BlogPostService 依赖于 db
def __init__(self, db):
self.db = db
def get_post(self, id):
return db.execute('SELECT * FROM post WHERE id = %s', [id]).fetchone()
def edit_post(self, id, content):
db.execute('UPDATE post SET content = %s WHERE id = %s', [content, id])
db.commit()
@app.get('/posts/<id>')
def read_post(id):
return g.blog_post_service.get_post(id)
@app.post('/posts/<id>/edit')
def edit_post(id):
g.blog_post_service.edit_post(id, request.form['content'])
return 'ok'
现在,http handler 服务员变薄了,它把所有与数据库相关的任务,都委派给了数据库服务员。强调一句,Spring 的编程范式,是大厅内存在很多单例 Service 作为服务员,我们与服务员通讯,服务员与自己依赖的其他服务员通讯。
单例服务员有许多好处。很重要的一点是,单元测试变得简单了。第一个例子中,想要测试那个统计最低价格的逻辑是否有误,无需 trip.example.com 在线;我们只要找个假的 TrainPriceService 和 FlightPriceService 对象(永远返回我们设定好的价格清单),提供给 CheapestPriceService ,就能对 CheapestPriceService 进行单元测试 。第二个例子,我们无需数据库在线,只需要找个假的 BlogPostService,就能对 http handler 进行单元测试。
依赖注入
单例服务员固然美好,但服务员 A 依赖于服务员 B、C,服务员 B 依赖于服务员 C、D、E……我们如果手动地按照拓扑序构造这些单例,则会增加代码的复杂程度。这时,Spring 的一个神奇功能出场了:依赖注入(dependency injection)。服务员只需要声明自己依赖于哪些其他服务员,Spring 会自动处理好一切。
举个例子。现在求 100 以内所有以 3 结尾的质数。那么我们先写两个 Service:质数检查器、尾数检查器。
@Service
public class PrimeNumberChecker {
public boolean check(int number) {
if (number < 2) return false;
for (int i = 2; i * i <= number; i++) {
if (number % i == 0) return false;
}
return true;
}
}
@Service
public class EndsWithThreeChecker {
public boolean check(int number) {
return number % 10 == 3;
}
}这里的 @Service 注解表示它希望被 Spring 管理。接下来,我们写个 PrimeFinderService,它通过构造函数,声明自己需要 PrimeNumberChecker 和 EndsWithThreeChecker,然后便可以直接引用这两个服务员:
@Service
public class PrimeFinderService {
private final PrimeNumberChecker primeChecker;
private final EndsWithThreeChecker endsWithThreeChecker;
public PrimeFinderService(PrimeNumberChecker pc, EndsWithThreeChecker etc) {
this.primeChecker = pc;
this.endsWithThreeChecker = etc;
}
public List<Integer> find(int start, int end) {
List<Integer> result = new ArrayList<>();
for (int i = start; i <= end; i++) {
if (primeChecker.check(i) && endsWithThreeChecker.check(i)) {
result.add(i);
}
}
return result;
}
}@Component、@Service 、@Repository、@RestController 等。它们都是被 Spring 管理的对象。搞懂了依赖注入,我们来编写第一个 Spring 程序。
第一个程序:命令行乘法器
本节我们写一个命令行程序,从 argv 接收两个整数 $a, b$,计算 $a\times b$ 并输出。为了减少样板代码,本文从现在开始使用 Kotlin,它也获得了 Spring 的一等公民支持。没有接触过 Kotlin 的读者可以去官方教程学习一番,大约需要几个小时。
打开 IDEA,创建 Spring Boot 应用,语言选 Kotlin,构建工具选 Gradle - Kotlin,JDK 选最新稳定版:
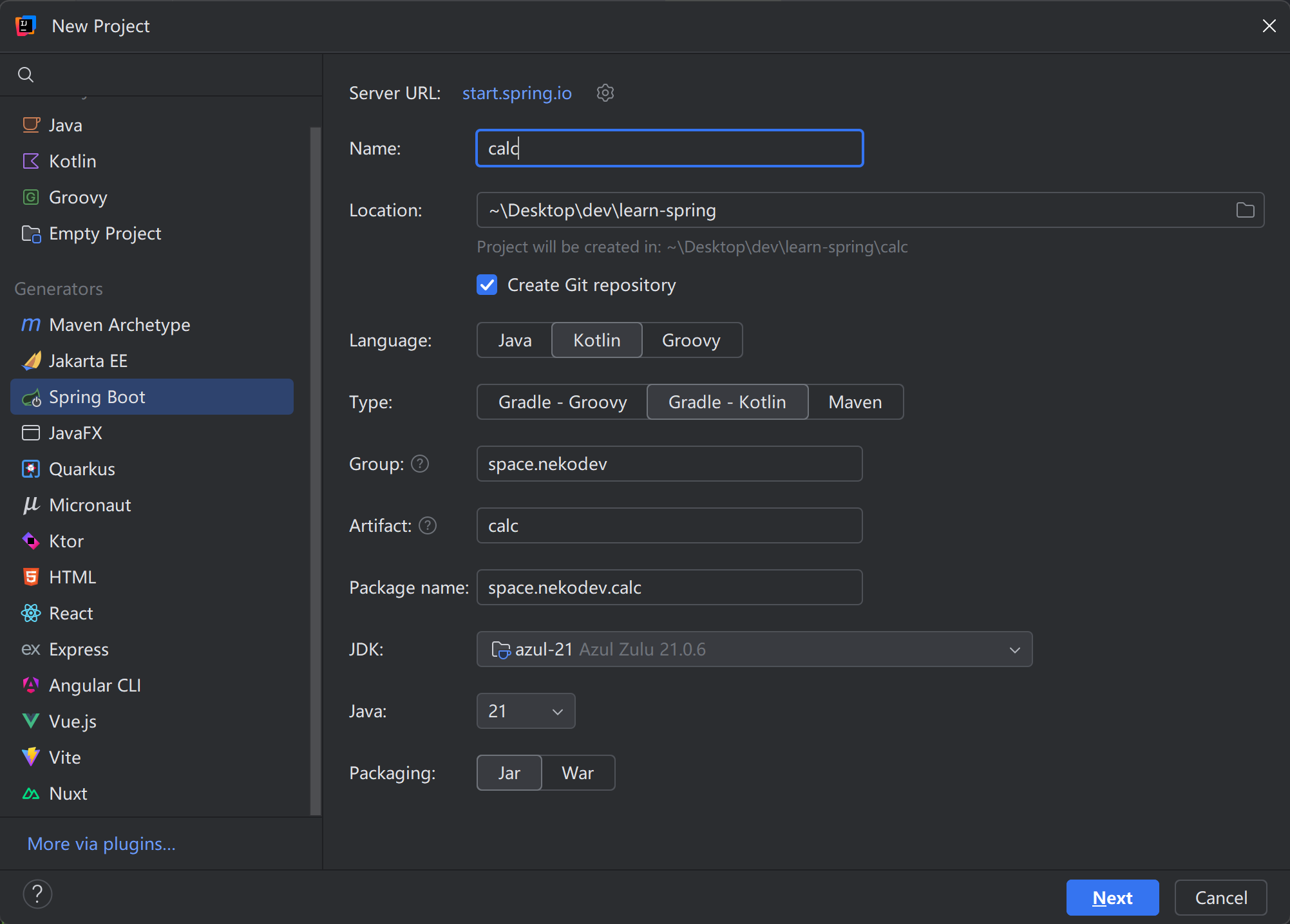
点击“Next”进入下面的界面。这里是用来选取 Spring MVC、Spring Data JDBC 等组件的,我们的计算器用不上这些,所以什么都不选,直接点击“Create”:
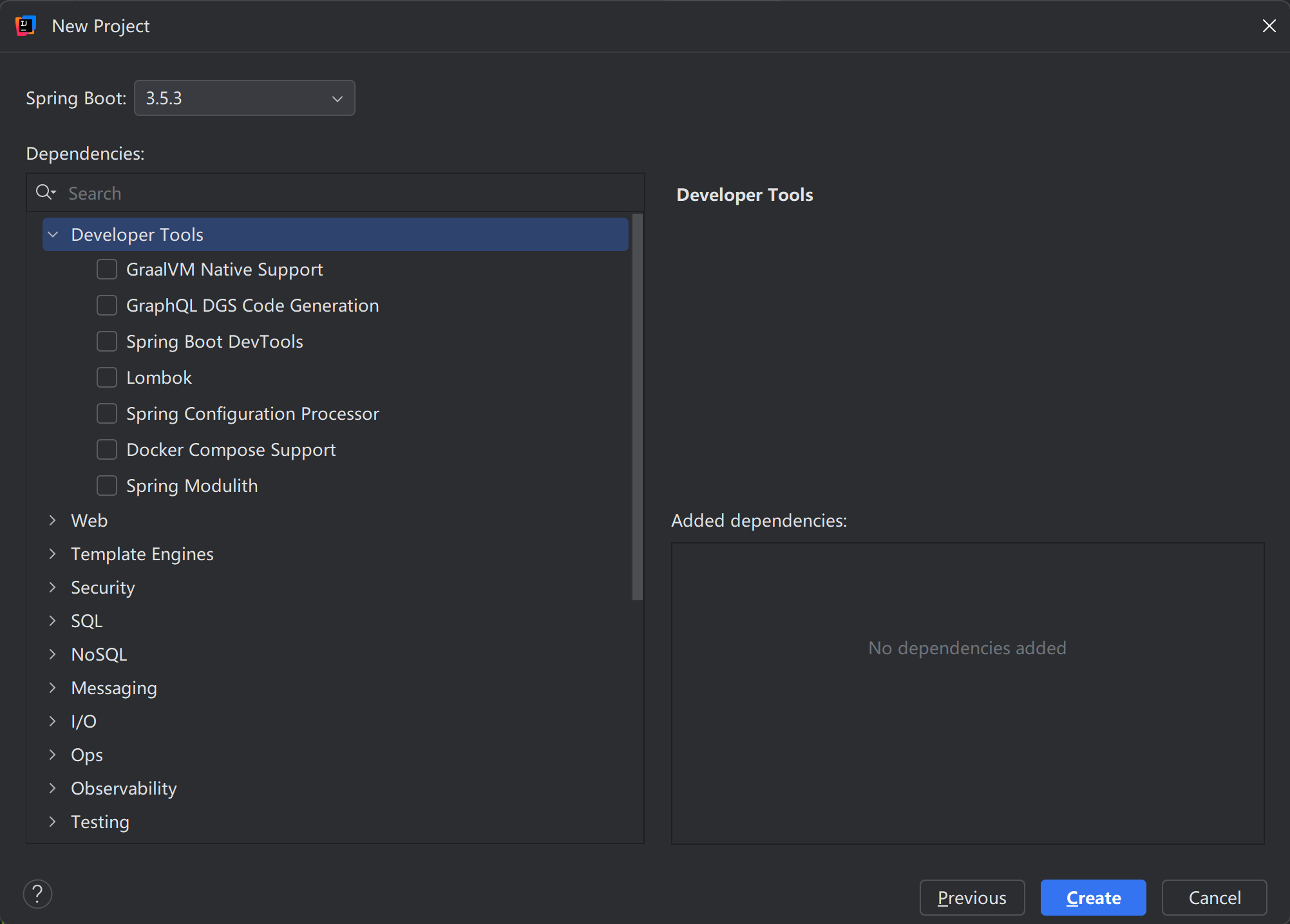
现在项目初始化完成。我们先观察一下 src 中唯一的文件 CalcApplication.kt :
package space.nekodev.calc
import org.springframework.boot.autoconfigure.SpringBootApplication
import org.springframework.boot.runApplication
@SpringBootApplication
class CalcApplication
fun main(args: Array<String>) {
runApplication<CalcApplication>(*args)
}简单解释一下上面的代码。@SpringBootApplication 表示这里有一个 Spring Boot 应用,需要扫描这个包(space.nekodev.calc)里的需要由 Spring 管理的类、执行自动配置。主函数就是把这个应用跑起来。
不过,我们其实不需要往这个 main 里面加代码。Spring 有个特性:只要你写个 Bean 实现 ApplicationRunner,那它的 run 方法就会在程序启动后被运行一次。这对于 Python 用户来说显得有些离谱——我都没调用它,它怎么开跑了?但这在 Spring 的世界里属于常规操作,我们以后还会见到更多的例子。这背后是 Spring 的一项设计哲学:“约定优于配置”,或者说,默认按约定行事,约定不够用了再考虑显式配置。
Spring 里有很多东西不是显式配置的,而是约定的。例如上面这个例子,Spring 约定,如果你的 Bean 实现了 ApplicationRunner,那 Spring 就会在所有 Bean 组装完成、应用就绪之后,运行你这个 Runner 的 run 方法。那我们可能会问,如果有多个任务需要按特定顺序执行,该怎么办?这时约定不够用了,才需要配置,使用 @Order(1) 、@Order(2) 注解来安排启动顺序。
编写 CalcRunner.kt :
package space.nekodev.calc
import org.springframework.boot.ApplicationArguments
import org.springframework.boot.ApplicationRunner
import org.springframework.stereotype.Component
@Component
class CalcRunner(
private val calcService: CalcService
) : ApplicationRunner {
override fun run(args: ApplicationArguments?) {
val (a, b) = args!!.sourceArgs.map { it.toInt() }
println(calcService.mul(a, b))
}
}它使用构造函数声明自己需要一个 CalcService,并在 run 方法中,把命令行参数的前两个整数相乘输出。最后,补上 CalcService.kt:
package space.nekodev.calc
import org.springframework.stereotype.Component
@Component
class CalcService {
fun mul(a: Int, b: Int) = a * b
}运行程序,我们可以看到 Spring 输出一些启动日志之后,确实执行了乘法运算:
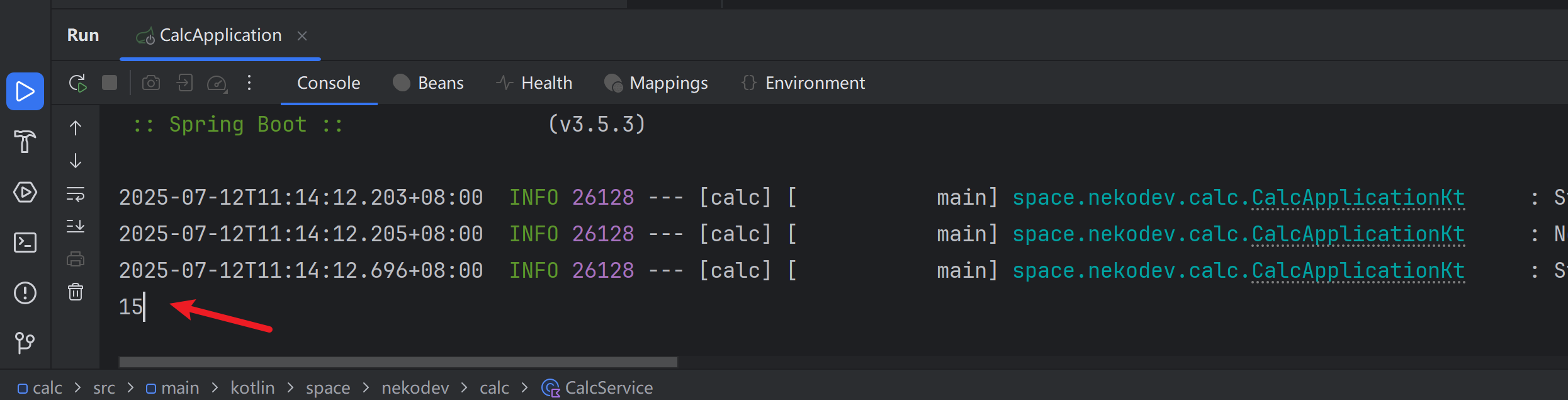
至此,我们已经熟知了 Spring 的核心理念,该开始用一个个小项目来触及更深层的知识了。笔者正巧近期有个“从互联网上搜集语料”的任务,大致是先头脑风暴想出一些关键词,然后使用搜索引擎搜索这些关键词,获得大量 url,把这些网页内容保存下来,以便未来作为 LLM 的知识库。
略算一笔:对于每 10 万个网页,假设每个网页占用 5 MB 空间,则总空间占用是 500 GB,若每次搜索获得 10 个 url,则需要执行 10000 次搜索。另外,抓取网页可能需要多个 worker 并行工作。所以,引入消息队列来管理搜索和抓取过程,是比较合适的。我们可以把整个语料爬虫划分为三个独立项目:
- 搜索器。从消息队列获取搜索请求,执行搜索,把搜到的 url 清单写进消息队列。
- 页面爬取器。从消息队列获取爬取请求,调用 Playwright 访问目标网页,把页面内容保存到 MinIO,并将保存后的 html、mhtml、pdf 等文件地址写进消息队列。
- 爬虫控制中心。它是一个 http 服务,允许用户发起搜索请求和爬取请求,并展示实时的任务情况。控制中心用关系型数据库维护任务状态。
在本文接下来的部分,我们会使用 Spring 实现这三个程序。消息队列选用 RabbitMQ,数据库选用 PostgreSQL。
本章小结:
- Spring 的程序里有很多个 Bean 单例(服务员),每个服务员可以依赖其他服务员。
- 实现了 ApplicationRunner 接口的 Bean 会在程序启动后被执行run方法。
- 使用 Spring Initializr 生成初始代码。IDEA 自带了这个东西。
搜索器
“网页搜索”在英文技术圈中称为 SERP,即 Search Engine Results Page。最自然的方案当然是调用 Google 和 Bing 的官方 API,想要什么数据有什么。然而,官方服务昂贵到不可接受:Google 的定价是每千次查询 5 USD,Bing 的典型价格是每千次查询 15 USD。我们只能另寻出路,假装自己是普通用户,用浏览器访问常规搜索页面,并 parse 出结果。不过,各大搜索引擎对这种行为都有拦截,如果我们不幸被拦截,则需要考虑第三方 SERP 提供商。他们会做 IP 轮换、验证码破解等工作,保证我们总是能正常获取到结果。第三方提供商的定价远低于官方,例如 Bright Data 是每千次请求 1.5 USD。
于是,我们的编程思路就是:同时提供“Playwright 模拟用户”、以及“调用 Bright Data”这两种实现,允许运行时选择使用哪个方案。从而,我们就需要有以下服务员:
- Playwright 服务员和 Bright Data 服务员,负责获取 html 格式的搜索结果
- 页面解析服务员,负责把 html 搜索结果解析成我们想要的对象(url、标题、摘要)
- 搜索服务员,依赖于上述两个服务员,提供搜索功能
- 任务接收服务员,负责消费消息队列,把任务转给搜索服务员
- 消息发送服务员,负责把搜索结果写入消息队列
开始实现这些服务员。创建项目,记得选中 RabbitMQ 和 WebFlux (我们需要使用其中的 WebClient 向 Bright Data 发起 http 请求),如果忘了选,也可以在 build.gradle.kts 里面添加:
dependencies {
// ...
implementation("org.springframework.boot:spring-boot-starter-amqp")
implementation("org.springframework.boot:spring-boot-starter-webflux")
}
先实现 Bright Data 服务员。
interface SerpFetcher {
fun fetchPage(url: String): String
}
@Component
class BrightDataFetcher(
@Value("\${brightdata.baseurl}") private val brightDataBaseUrl: String,
@Value("\${brightdata.zone}") private val brightDataZone: String,
@Value("\${brightdata.apikey}") private val brightDataApiKey: String,
) : SerpFetcher {
override fun fetchPage(url: String): String {
val exchangeStrategies = ExchangeStrategies.builder()
.codecs { configurer ->
// buffer 开到 16 MB(默认的 256 KB 不够保存响应报文)
configurer.defaultCodecs().maxInMemorySize(16 * 1024 * 1024)
}.build()
val client = WebClient.builder()
.baseUrl(brightDataBaseUrl)
.exchangeStrategies(exchangeStrategies)
.build()
val requestBody = mapOf(
"zone" to brightDataZone,
"url" to url,
"format" to "raw"
)
val response = client.post()
.uri("/request")
.header("Authorization", brightDataApiKey)
.header("Content-Type", "application/json")
.body(BodyInserters.fromValue(requestBody))
.retrieve()
.bodyToMono(String::class.java)
.block()
return response!!
}
}上面的代码中,我们使用了 WebClient 来发起请求,它是 Spring WebFlux 自带的 HTTP 客户端。这个 BrightDataFetcher 的构造函数中有几个 @Value,它是用来把配置文件中指定的值注入给 Bean 的。我们编写 src/main/resources/application.yml :
brightdata:
baseurl: "https://api.brightdata.com"
zone: "serp_api1"
apikey: "Bearer 75******************************5a"用 @Value("\${brightdata.apikey}") 注入之后,代码中就可以访问 brightDataApiKey 了。而且,在运行时,我们还可以用环境变量 BRIGHTDATA_APIKEY 覆盖掉源码文件中指定的值,这也是“约定优于配置”的又一实例。
.properties 配置文件和较新的 .yml 配置文件,有很多地方可以放置配置文件(例如源码包中、运行时目录下、环境变量)。详询 LLM。接下来给 BrightDataFetcher 写测试:
@SpringBootTest
class BrightDataFetcherTest {
@Autowired
private lateinit var brightDataFetcher: BrightDataFetcher
@Test
fun `simple search test`() {
// 搜索“法国首都”,期望返回内容中包含“巴黎”
val res =
brightDataFetcher.fetchPage("https://cn.bing.com/search?q=%E6%B3%95%E5%9B%BD%E9%A6%96%E9%83%BD&first=1")
assertContains(res, "巴黎")
}
}
测试类依赖于 BrightDataFetcher 类,但这里我们没有使用构造函数注入,而是用 @Autowired 直接注入到成员变量。网上的代码很多都是这样的写法,这是因为 JUnit 4 要求测试类的构造函数必须无参。当然,我们正在使用 JUnit 5,它已经支持了构造函数注入,所以下面的写法更现代也更推荐:
@SpringBootTest
class BrightDataFetcherTest @Autowired constructor(private val brightDataFetcher: BrightDataFetcher) {
// ...
}关于 @Autowired 的更详细情况,可以咨询 LLM。新代码中应当尽力避免 @Autowired 直接注入成员变量。接下来实现 PlaywrightFetcher:
@Component
class PlaywrightFetcher : SerpFetcher {
override fun fetchPage(url: String): String {
Playwright.create().use { playwright ->
val browser = playwright.firefox().launch()
val page = browser.newPage()
page.navigate(url)
page.waitForLoadState()
sleep(5000)
return page.content()
}
}
}单元测试同上,不再赘述。现在我们有了 SerpFetcher 的两个实现,来编写 parser。逻辑可以参考 Cherry Studio 大模型搜索功能的实现:
data class SearchResultItem(
val url: String,
var title: String
)
@Component
class BingParser {
fun parse(html: String): List<SearchResultItem> {
val items = Jsoup.parse(html).select("#b_results h2")
return items.mapNotNull { h2 ->
h2.selectFirst("a")?.let { a ->
SearchResultItem(
title = a.text(),
url = a.attr("href")
)
}
}
}
}接下来编写我们的搜索服务。它接收关键词和页码数,然后构造出 url,交给 SerpFetcher 去爬取,调用 parser 解析出搜索结果清单。不过,在那之前,我们先解决“二选一”的问题。搜索服务只需要一个 SerpFetcher,而不关心具体是哪个 fetcher;我们让 Spring 根据配置文件只构建特定的 fetcher 实例,而不构建另一个。先修改两个 fetcher 类的定义,添加 @ConditionalOnProperty 注解:
@Component
@ConditionalOnProperty(name = ["serp.fetcher.type"], havingValue = "playwright")
class PlaywrightFetcher : SerpFetcher { ... }
@Component
@ConditionalOnProperty(name = ["serp.fetcher.type"], havingValue = "brightdata")
class BrightDataFetcher(...) { ... }于是,Spring 初始化时,会去看 serp.fetcher.type 配置,实例化这两个 fetcher 中的一个。不过,此时我们的测试代码被破坏了,因为测试时可能没有它所需要的那个 fetcher。我们修改测试代码,用 @TestPropertySource 指定配置项:
@SpringBootTest
@TestPropertySource(properties = ["serp.fetcher.type = brightdata"])
class BrightDataFetcherTest @Autowired constructor(private val brightDataFetcher: BrightDataFetcher) { ... }
// PlaywrightFetcherTest 同理接下来,我们就能注入 SerpFetcher 了:
@Service
class SearchService(
private val serpFetcher: SerpFetcher,
private val bingParser: BingParser,
) {
fun buildUrl(keywords: String, page: Int): String {
val offset = when (page) {
1 -> 1
else -> (page - 1) * 10
}
return UriComponentsBuilder
.fromUriString("https://cn.bing.com/search")
.queryParam("q", keywords)
.queryParam("first", offset)
.encode()
.build()
.toUriString()
}
fun search(keywords: String, page: Int): List<SearchResultItem> {
val url = buildUrl(keywords, page)
val html = serpFetcher.fetchPage(url)
return bingParser.parse(html)
}
}代码本身可以正常运行,然而,IDEA 会提示 SerpFetcher 有多个候选:
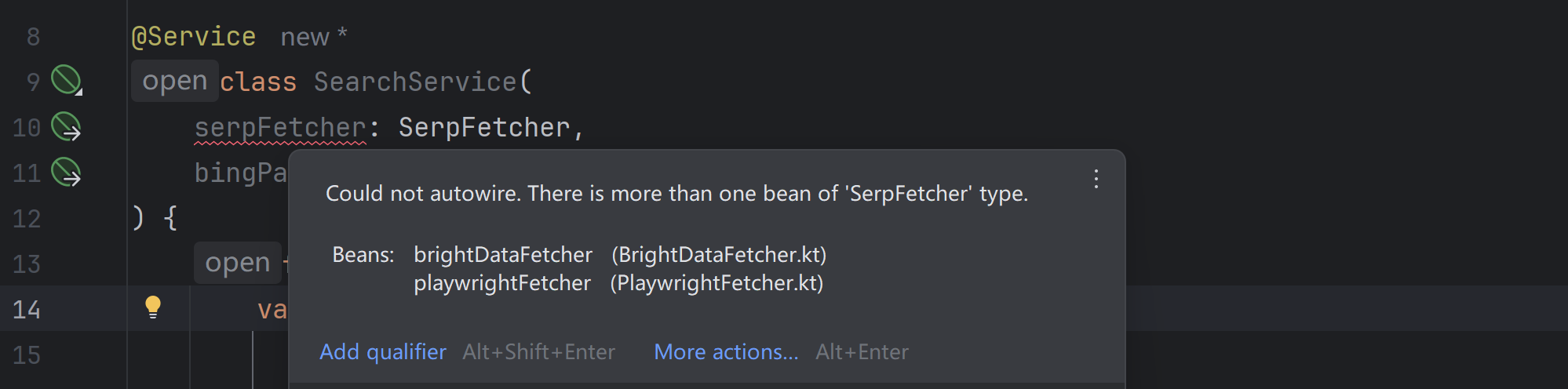
查阅资料,发现 IDEA 目前是不做这方面检查的。想要在 IDEA 中消除警告,我们可以在 PlaywrightFetcher 上添加一个 @Primary 注解,让 IDEA 假装它是优先实现。
现在我们有了 SearchService,剩余的工作就是处理消息队列。如果我们直接使用 RabbitMQ 官方提供的 Java 客户端 amqp-client ,则会比较复杂(需要自行实现 DefaultConsumer 等)。Spring 好就好在生态,我们有 Spring AMQP 帮助程序员简化代码。先在 application.yml 配置 RabbitMQ 连接参数:
spring:
rabbitmq:
host: 192.168.*.*
port: 5672
username: neko
password: ***************声明接收队列和发送队列(durable=true 表示队列是持久化的,在 RabbitMQ 重启后仍然存在)、配置自动序列化/反序列化:
@Configuration
class RabbitMQConfig {
@Bean
fun searchRequestQueue(): Queue {
return Queue("search_request", true)
}
@Bean
fun searchResponseQueue(): Queue {
return Queue("search_response", true)
}
@Bean
fun jsonMessageConverter(): MessageConverter {
return Jackson2JsonMessageConverter()
}
}接下来,实现消息发送器:
data class SearchResultMqDto(
val id: String,
val status: String,
val items: List<SearchResultItem>
)
@Service
class SearchResponseSender(private val rabbitTemplate: RabbitTemplate) {
private val log = LoggerFactory.getLogger(javaClass)
fun send(message: SearchResultMqDto) {
log.info("send: {}", message)
rabbitTemplate.convertAndSend("search_response", message)
}
}实现消息接收器:
data class SearchRequestMqDto(
val id: String,
val keywords: String,
val page: Int
)
@Service
class SearchRequestReceiver(
private val searchService: SearchService,
private val searchResponseSender: SearchResponseSender
) {
private val log = LoggerFactory.getLogger(javaClass)
@RabbitListener(queues = ["search_request"])
fun receive(request: SearchRequestMqDto) {
log.info("recv: {}", request)
try {
val items = searchService.search(request.keywords, request.page)
searchResponseSender.send(SearchResultMqDto(request.id, "ok", items))
} catch (e: Exception) {
searchResponseSender.send(SearchResultMqDto(request.id, e.toString(), emptyList()))
}
}
}使用 RabbitMQ 自带的 Web UI 向 search_request 队列发送一条请求,几秒之后在 search_response 队列收到结果:
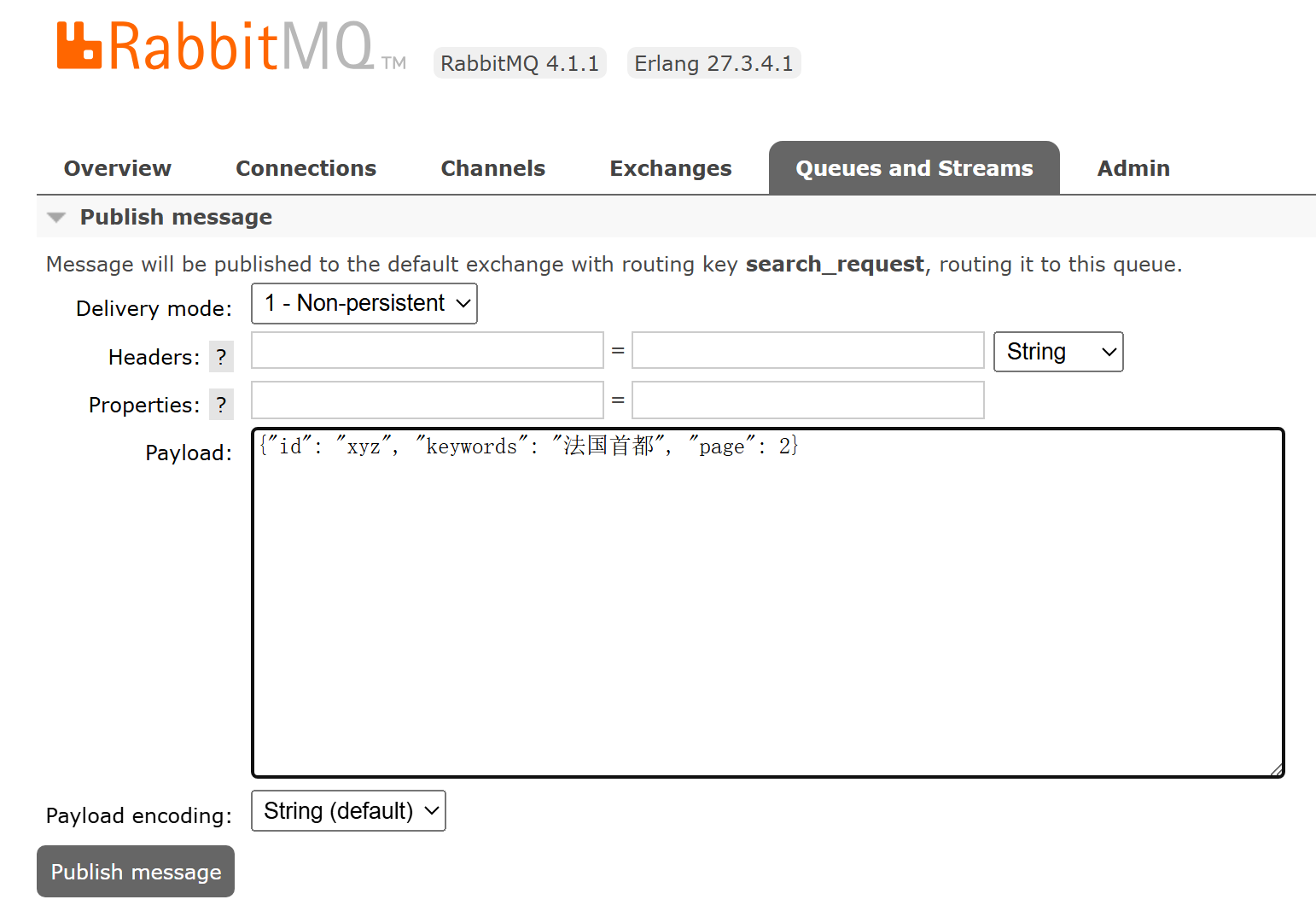
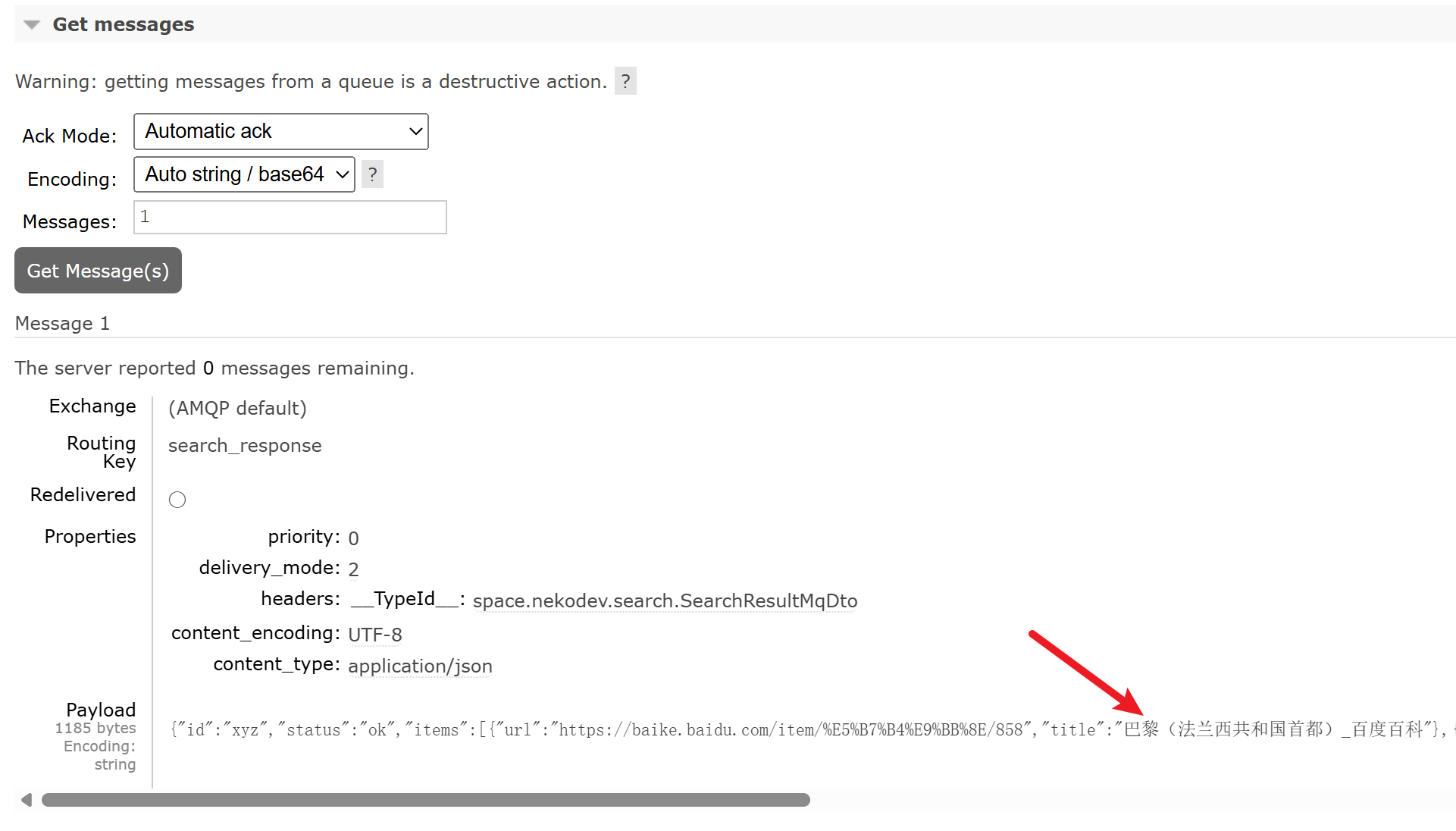
至此,我们的搜索器开发完成。不过,我们总不能用 IDEA 来运行这个服务,得把程序转移到服务器上去。Spring Boot 已经准备好了 gradle 配置,可以用 bootJar 任务,将代码打包成一个 fat jar:
不过,当我们运行起来这个 jar 时,会发现它竟然监听了 8080 端口。这是因为,最初我们想使用 WebClient,所以引入了 spring-boot-starter-webflux;而根据约定,它默认会启动一个 Netty 服务器。这又是“约定优于配置”在作祟,我们需要配置 application.yml,禁用掉这一默认行为:
spring:
main:
web-application-type: none再次打包,发现程序不会监听 8080 了。写 /etc/systemd/system/search-service.service 配置服务:
[Unit]
Description=Search Service
[Service]
ExecStart=/usr/bin/java -jar /home/neko/app/search-service/search-0.0.1-SNAPSHOT.jar
Restart=always
User=neko
[Install]
WantedBy=multi-user.target解决掉一些 playwright 依赖问题之后,搜索器成功响应了请求。
本章小结:
- 规划项目时,先想好我们需要哪些 Bean,列出它们之间的依赖关系。
- 除了构造函数注入之外,还可以通过@Autowired直接注入属性,但是不推荐。
- 测试时,使用@SpringBootTest注解。Spring 会帮我们注入依赖。
- 在application.yml里定义一些配置项。可以通过环境变量等方式在运行时覆盖之。
- Spring 可以按配置项来决定一个 Bean 要不要被实例化。
- 如果 Spring 生态中提供了某个组件的官方集成,则毫不犹豫地选择它,以避免跟组件的原始 API 打交道。
- 使用 bootJar 把程序打包成 fat jar,不要用 shadow。
页面爬取器
接下来实现页面爬取功能。仍然是使用 Playwright 抓取网页,抓取后把 html、mhtml、pdf 上传到 MinIO。另外,需要允许用户在配置文件中指定这几种文件的最大尺寸,如果超过尺寸,则不保存。还要允许指定 http 请求超时时间。
整理一下所需的 Bean:
- 网页爬取服务。访问某 url 并返回 html、mhtml 和 pdf。
- 文件上传服务。把文件上传到 MinIO,若超过尺寸限制则拒绝上传。
- 任务接收服务。
- 任务结果发送服务。
先实现网页爬取服务。Playwright 可以通过 CDP 来抓取 mhtml(是一个网页归档格式,包含样式、图像等内容),不过仅 Chromium 浏览器支持。代码实现如下:
class WebPageContent(
val html: String,
val mhtml: String,
val pdf: ByteArray,
)
@Component
class PlaywrightFetcher(
@Value("\${playwright.wait-seconds}") private val waitSeconds: Long,
@Value("\${playwright.timeout-seconds}") private val timeoutSeconds: Long,
) {
private val log = LoggerFactory.getLogger(javaClass)
fun get(url: String): WebPageContent {
log.info("GET $url")
Playwright.create().use { playwright ->
val browser = playwright.chromium().launch()
val context = browser.newContext(
Browser.NewContextOptions().apply {
setViewportSize(1920, 1080)
}).apply {
setDefaultTimeout(timeoutSeconds * 1000.0)
}
val page = context.newPage().apply {
navigate(url)
waitForLoadState()
}
sleep(waitSeconds * 1000)
val capture = context.newCDPSession(page).send("Page.captureSnapshot")
return WebPageContent(
page.content(), capture.get("data").toString(), page.pdf()
).also {
log.info("fetched $url | file size: html ${it.html.length}, mhtml ${it.mhtml.length}, pdf ${it.pdf.size}")
}
}
}
}然后实现 MinIO 服务。Spring 没有对 S3 进行官方集成,我们要使用原始 API:
@ConfigurationProperties(prefix = "minio")
data class MinioProperties(
val endpoint: String,
val accessKey: String,
val secretKey: String,
val bucket: String,
val sizeLimits: Map<String, Long> = emptyMap()
)
@Configuration
class MinioConfig(
private val conf: MinioProperties,
) {
@Bean
fun s3Client(): S3Client {
val credentials = AwsBasicCredentials.create(conf.accessKey, conf.secretKey)
return S3Client.builder()
.region(Region.of("us-east-1"))
.credentialsProvider(StaticCredentialsProvider.create(credentials))
.endpointOverride(URI.create(conf.endpoint))
.forcePathStyle(true)
.build()
}
}
@Service
class MinioService(
private val conf: MinioProperties,
private val s3Client: S3Client
) {
private val log = LoggerFactory.getLogger(javaClass)
fun upload(fileType: String, content: ByteArray): String {
val fileName = "${UUID.randomUUID().toString()}.$fileType"
val sizeLimit = conf.sizeLimits[fileType] ?: conf.sizeLimits["any"]!!
log.info("Uploading [$fileName]: size = ${content.size} limit = $sizeLimit")
if (content.size > sizeLimit) {
log.info("Canceled [$fileName]: file size exceeds limit")
throw IllegalArgumentException("File size exceeds limit")
}
s3Client.putObject(
PutObjectRequest.builder()
.bucket(conf.bucket)
.key(fileName)
.build(),
RequestBody.fromBytes(content)
)
return fileName
}
}详细解释一下上述代码。我们这次用 @ConfigurationProperties 而不是 @Value 来获取配置项,因为这次的配置比较复杂:
minio:
endpoint: http://192.168.***.***:9000
access-key: neko
secret-key: **************
bucket: corpus
size-limits:
any: 10
html: 1000000
mhtml: 5000000
pdf: 10000000@ConfigurationProperties 能将这样的配置映射到对象,我们其他 Bean 只需要依赖 MinioProperties,无需用 @Value 分别列举每一条配置。 不过,要使用这个特性,我们需要给主程序一个 @ConfigurationPropertiesScan 注解,方可起效:
@SpringBootApplication
@ConfigurationPropertiesScan
class FetchApplication在代码中,我们编写了 MinioConfig ,其中用一个带有 @Bean 注解的函数,实例化了一个 S3Client。于是,现在 Spring 世界里就有了 S3Client 类的单例,我们以后就可以直接依赖 S3Client 了。用 @Configuration 和 @Bean 来把第三方对象放进 Spring,是很常见的做法。
接下来是 RabbitMQ 相关服务。先注册两个队列:
@Configuration
class RabbitMQConfig {
@Bean
fun fetchRequestQueue(): Queue {
return Queue("fetch_request", true)
}
@Bean
fun fetchResponseQueue(): Queue {
return Queue("fetch_response", true)
}
@Bean
fun jsonMessageConverter(): MessageConverter {
return Jackson2JsonMessageConverter()
}
}任务结果发送服务:
data class FetchResultMqDto(
val id: String, val status: String, val files: Map<String, String>
)
@Service
class FetchResponseSender(private val rabbitTemplate: RabbitTemplate) {
private val log = LoggerFactory.getLogger(javaClass)
fun send(message: FetchResultMqDto) {
log.info("send: {}", message)
rabbitTemplate.convertAndSend("fetch_response", message)
}
}任务接收服务:
data class FetchRequestMqDto(
val id: String,
val url: String,
)
@Service
class SearchRequestReceiver(
private val playwrightFetcher: PlaywrightFetcher,
private val minioService: MinioService,
private val fetchResponseSender: FetchResponseSender
) {
private val log = LoggerFactory.getLogger(javaClass)
@RabbitListener(queues = ["fetch_request"])
fun receive(request: FetchRequestMqDto) {
log.info("recv: {}", request)
try {
val pageContent = playwrightFetcher.get(request.url)
val files: Map<String, String> = buildMap {
fun tryUpload(fileType: String, content: ByteArray) {
try {
put(fileType, minioService.upload(fileType, content))
} catch (_: IllegalArgumentException) {
}
}
pageContent.run {
tryUpload("html", html.toByteArray())
tryUpload("mhtml", mhtml.toByteArray())
tryUpload("pdf", pdf)
}
}
log.info("files: $files")
fetchResponseSender.send(FetchResultMqDto(request.id, "ok", files))
} catch (e: Exception) {
fetchResponseSender.send(FetchResultMqDto(request.id, e.toString(), emptyMap()))
}
}
}现在所有 Bean 都已实现,打包成 bootJar,传到服务器上运行。我们只剩下爬虫控制中心待实现了。
本章小结:
- 使用@ConfigurationProperties来把配置文件映射到对象。需要给主程序开启@ConfigurationPropertiesScan注解。
- 想要让 Spring 管理一个第三方类的单例,可以在@Configuration类中实现一个带有@Bean注解的函数,它返回的那个对象将会作为该类型的单例。
爬虫控制中心
本文有意把爬虫控制中心这个 web 服务放到最后来写,因为 web 开发绝非 Spring Boot 的全部。在当今的中文互联网上,提起 Spring Boot 几乎就等同于 Spring MVC,这是不合理的。我们前两个应用程序都没有使用 Spring MVC,但都享受到了 Spring 生态带来的好处。
本节中,我们将会构造一个 Restful API 服务,它拥有以下 API:
- POST
/ping,返回问候语。 - GET
/search-tasks/stats,返回搜索任务的整体统计状况(有多少任务正在执行等)。 - GET
/search-tasks/<uuid>,返回特定搜索任务的状态。 - GET
/search-tasks?page=<x>&size=<y>,返回第 x 页搜索任务,每页 y 行。 - POST
/search-tasks,创建一个搜索任务。 - 爬取任务的四个 API,略。
爬虫控制中心一方面要应付用户的 http 请求,另一方面要监听消息队列。一场完整的搜索过程如下:用户 POST /search-tasks;控制中心把这个请求记录到数据库,并向消息队列发送任务;控制中心从消息队列监听到任务完成,把结果更新到数据库。
梳理明白后,我们来设计 Bean:
- 数据库服务,负责读写 PostgreSQL。
- 搜索任务、爬取任务的 RabbitMQ 服务。它们需要在收到结果后更新数据库,所以它们也依赖数据库服务。
- web 服务,是一个
@RestController,负责与用户交互。依赖数据库服务和两个 RabbitMQ 服务。
这样看来,我们应该先实现数据库服务,再实现 RabbitMQ 相关的两个服务,最后实现 web 服务。
数据库服务
在讨论数据库服务如何实现之前,笔者先介绍一下 Java 中如何访问关系型数据库。JDBC 是一个通用的数据库接口,类似于 Golang 中的 database/sql;各种关系型数据库都会有符合 JDBC 接口的驱动,例如 pgJDBC。然而,JDBC 的 API 过于原始,开发者一般都会采用更抽象的访问方式(即各类 ORM)。以 MyBatis 为例,它有两个层:底层是 xml 文件,用户在 xml 中编写具体的 SQL 语句,并指定输入参数类型和输出参数类型;上层是 Mapper 类,它是与其他 Java 代码交互的接口,定义了各种方法,签名与 xml 文件里的一致,但是 Mapper 类中不直接写 SQL。这样,用户就可以调用 userMapper.selectById(1) 来直接获取到一个 User 对象,而不是用 JDBC 执行 SQL 语句并调用 resultSet.getString("name") 等繁琐的接口来组装 User 对象。Java ORM 这方面,MarcoBehler 著有一篇概述,一定要读一遍。
本文选择的数据库访问方案是 Spring Data JDBC,它是一个 ORM 框架,可以自动进行 Java 类与数据行之间的映射。之所以选择它,是因为它能自动生成 getById 这样的简单语句,同时也允许开发者控制最底层的 SQL。对我们的应用来说,Spring Data JPA 实在是太重了。
配置 yml 文件:
spring:
datasource:
url: jdbc:postgresql://192.168.***.***:5432/spider
username: postgres
password: *****************
sql:
init:
mode: always设计表。把建表语句放在 src/main/resources/schema.sql 下,由于我们刚刚配置了 sql.init.mode=always,Spring Boot 会自动执行它:
CREATE TABLE IF NOT EXISTS search_task
(
id SERIAL PRIMARY KEY,
mq_id TEXT NOT NULL,
keywords TEXT NOT NULL,
page INTEGER NOT NULL,
state TEXT NOT NULL, -- running, ok, failed
result TEXT, -- 搜索器返回的状况,ok 或报错
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP
);定义一个相应的 model:
@Table("search_task")
data class SearchTask(
@Id
var id: Long? = null,
val mqId: String,
val state: String,
val keywords: String,
val page: Int,
val result: String? = null,
val createdAt: Instant? = null,
val updatedAt: Instant? = null
)接下来,定义一个接口 SearchTaskRepository,继承 CrudRepository<SearchTask, Long>:
interface SearchTaskRepository : CrudRepository<SearchTask, Long> {
fun count(): Int
fun countByState(state: String): Int
fun getByMqId(mqId: String): SearchTask
@Modifying
@Query("INSERT INTO search_task (mq_id, state, keywords, page) VALUES (:mqId, 'running', :keywords, :page)")
fun insertNewTask(mqId: String, keywords: String, page: Int)
}我们的接口一旦继承了 CrudRepository<SearchTask, Long>,便获得了自动生成 SQL 的能力。例如,我们可以声明 countByState 这样的方法但不实现,Spring Data JDBC 会自动提供实现。除此以外,还可以手写 SQL,例如上面的 insertNewTask。这个 repository 的使用也很简单:
searchTaskRepository.insertNewTask("hello", "法国首都", 1)
println(searchTaskRepository.countByState("running"))
println(searchTaskRepository.getByMqId("123-456-789"))回过头去看我们那几个 API,实际上搜索任务的 repository 只需要提供以下几个接口:insertNewTask、updateTaskResult、count、countByState、getByMqId、findAll,其中前两个接口我们手写;findAll 需要支持分页查询。Spring Boot JDBC 有一个接口 PagingAndSortingRepository 继承了 CrudRepository,是用来帮我们实现分页和排序的。把代码改成:
interface SearchTaskRepository : PagingAndSortingRepository<SearchTask, Long> {
fun count(): Int
fun countByState(state: String): Int
fun getByMqId(mqId: String): SearchTask
@Modifying
@Query("INSERT INTO search_task (mq_id, state, keywords, page) VALUES (:mqId, 'running', :keywords, :page)")
fun insertNewTask(mqId: String, keywords: String, page: Int)
@Modifying
@Query("UPDATE search_task SET state = :state, result = :result, updated_at = CURRENT_TIMESTAMP WHERE id = :id")
fun updateTaskResult(id: Long, state: String, result: String)
}Spring Data JDBC 会自动生成 findAll 方法,这样使用:
searchTaskRepository.findAll(PageRequest.of(0, 5, Sort.by("id")))
至此,我们完全实现了 SearchTaskRepository,在这过程中只手写了两个 SQL 语句。接下来编写单元测试,我们希望在测试时使用内存数据库而不是 PostgreSQL。这也很好办,先添加 H2 数据库依赖,用 testImplementation 表示它仅在测试时需要:
testImplementation("com.h2database:h2")
编辑 application.yml,用 --- 隔开一个专用于测试的配置:
spring:
datasource:
url: jdbc:postgresql://192.168.***.***:5432/spider
username: postgres
password: *****************
sql:
init:
mode: always
# 注意下面的部分
---
spring:
config:
activate:
on-profile: test
datasource:
url: jdbc:h2:mem:testdb;MODE=PostgreSQL;DB_CLOSE_DELAY=-1;DB_CLOSE_ON_EXIT=false;DATABASE_TO_LOWER=true;CASE_INSENSITIVE_IDENTIFIERS=true;
username: sa
password: password
sql:
init:
mode: always
编写测试用例:
@SpringBootTest
@ActiveProfiles("test")
class SearchTaskRepositoryTest @Autowired constructor(private val searchTaskRepository: SearchTaskRepository) {
@Test
fun test() {
searchTaskRepository.insertNewTask("a", "aaa", 1)
searchTaskRepository.insertNewTask("b", "bbb", 2)
searchTaskRepository.insertNewTask("c", "ccc", 3)
searchTaskRepository.insertNewTask("d", "ddd", 4)
searchTaskRepository.insertNewTask("e", "eee", 5)
searchTaskRepository.insertNewTask("f", "fff", 6)
searchTaskRepository.insertNewTask("g", "ggg", 7)
assertEquals(7, searchTaskRepository.count())
assertEquals(7, searchTaskRepository.countByState("running"))
searchTaskRepository.updateTaskResult(
searchTaskRepository.getByMqId("a").id!!, "ok", "ok"
)
assertEquals(6, searchTaskRepository.countByState("running"))
assertEquals(1, searchTaskRepository.countByState("ok"))
val res = searchTaskRepository.findAll(PageRequest.of(0, 5, Sort.by("id").descending()))
assertEquals(2, res.totalPages)
assertEquals(7, res.totalElements)
assertEquals(5, res.numberOfElements)
assertEquals(res.content[0].mqId, "g")
}
}
接下来实现 search_result_item 表相关的 CRUD:
CREATE TABLE IF NOT EXISTS search_result_item
(
id SERIAL PRIMARY KEY,
task_id INTEGER NOT NULL,
url TEXT NOT NULL,
title TEXT NOT NULL
);
@Table("search_result_item")
data class SearchResultItem(
@Id
var id: Long? = null,
val taskId: Long,
val url: String,
val title: String
)
interface SearchResultItemRepository: CrudRepository<SearchResultItem, Long> {
fun findAllByTaskId(taskId: Long): List<SearchResultItem>
}
Spring Data JDBC 提供了 save 方法,用于把对象保存到数据库。调用时,使用 repo.save(obj),例如:
@SpringBootTest
@ActiveProfiles("test")
class SearchResultItemTest @Autowired constructor(private val searchResultItemRepository: SearchResultItemRepository) {
@Test
fun test() {
val it = SearchResultItem(
taskId = 233,
url = "https://www.example.com",
title = "example",
)
searchResultItemRepository.save(it)
assertEquals("example", searchResultItemRepository.findAllByTaskId(233).first().title)
val items = listOf(
SearchResultItem(null, 456, "url", "title"),
SearchResultItem(null, 789, "url", "title")
)
searchResultItemRepository.saveAll(items)
assertEquals(3, searchResultItemRepository.findAll().toList().size)
}
}
save 方法的坑非常多。例如:它要求主键是由数据库自动生成的(即执行 save 方法时,对象中的主键必须为 null);它会更新所有字段,不支持部分更新。如果读者跟笔者一样对 SQL 有洁癖,则强烈建议对插入和更新手写 SQL。最后是 fetch_task 表:
CREATE TABLE IF NOT EXISTS fetch_task
(
id SERIAL PRIMARY KEY,
mq_id TEXT NOT NULL,
url TEXT NOT NULL,
state TEXT NOT NULL, -- running, ok, failed
result TEXT, -- 爬取器返回的状况,ok 或报错
filename_html TEXT,
filename_shtml TEXT,
filename_pdf TEXT,
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP
);
@Table("fetch_task")
data class FetchTask(
@Id
var id: Long? = null,
val mqId: String,
val url: String,
val state: String,
val result: String? = null,
val filenameHtml: String? = null,
val filenameShtml: String? = null,
val filenamePdf: String? = null,
val createdAt: Instant? = null,
val updatedAt: Instant? = null
)
interface FetchTaskRepository : PagingAndSortingRepository<FetchTask, Long> {
fun count(): Int
fun countByState(state: String): Int
fun getByMqId(mqId: String): FetchTask
@Modifying
@Query("INSERT INTO fetch_task (mq_id, state, url) VALUES (:mqId, 'running', :url)")
fun insertNewTask(mqId: String, url: String)
@Modifying
@Query("""
UPDATE fetch_task
SET
state = :state,
result = :result,
updated_at = CURRENT_TIMESTAMP,
filename_html = :filenameHtml,
filename_shtml = :filenameShtml,
filename_pdf = :filenamePdf
WHERE mq_id = :mqId
""")
fun updateTaskResult(mqId: String, state: String, result: String, filenameHtml: String?, filenameShtml: String?, filenamePdf: String?)
}
至此,我们的 Repository 层已经实现。在 Repository 之上构建 Service:
@Service
class SearchTaskDbService(
private val searchTaskRepository: SearchTaskRepository,
private val searchResultItemRepository: SearchResultItemRepository
) {
fun statisticsInfo() = mapOf(
"total" to searchTaskRepository.count(),
"running" to searchTaskRepository.countByState("running"),
"ok" to searchTaskRepository.countByState("ok"),
"failed" to searchTaskRepository.countByState("failed")
)
fun createNewTask(keywords: String, page: Int): String {
val mqId = UUID.randomUUID().toString()
searchTaskRepository.insertNewTask(mqId, keywords, page)
return mqId
}
fun getTask(mqId: String) = searchTaskRepository.getByMqId(mqId)
fun getRecentTasks(page: Int, pageSize: Int) =
searchTaskRepository.findAll(PageRequest.of(page, pageSize, Sort.by("id").descending()))
fun getSearchResultItemsForTask(taskId: Long) = searchResultItemRepository.findAllByTaskId(taskId)
@Transactional
fun updateTaskResult(dto: SearchResultMqDto) {
val state = if (dto.status == "ok") "ok" else "failed"
val taskId = searchTaskRepository.getByMqId(dto.id).id!!
searchTaskRepository.updateTaskResult(
taskId,
state,
dto.status
)
dto.items.forEach { item ->
searchResultItemRepository.save(SearchResultItem(
taskId = taskId,
url = item.url,
title = item.title,
))
}
}
}
上面的代码中用到了 @Transactional 注解,使用它时,我们需要在主程序类上添加 @EnableTransactionManagement,以开启 Spring 的事务管理功能。被 @Transactional 注解的方法,会把所有数据库操作放在同一个事务中进行,从而确保数据一致性。
@Transactional 另一个好处是,如果我们在测试类上使用它,则测试完成后会自动回滚。我们有必要在本项目的所有数据库相关测试类中使用 @Transactional ,否则会出现“每个用例都能独自成功运行,但批量运行所有用例时会失败”的奇观。集成测试:
@SpringBootTest
@ActiveProfiles("test")
class SearchTaskDbServiceTest @Autowired constructor(private val searchTaskDbService: SearchTaskDbService) {
@Test
fun test() {
assertEquals(0, searchTaskDbService.statisticsInfo()["total"])
val uuid = searchTaskDbService.createNewTask("aaa", 1)
assertEquals("aaa", searchTaskDbService.getTask(uuid).keywords)
assertEquals(1, searchTaskDbService.statisticsInfo()["running"])
searchTaskDbService.updateTaskResult(
SearchResultMqDto(
uuid,
"ok",
listOf(
SearchResultItemMqDto("https://a.example.com", "page a"),
SearchResultItemMqDto("https://b.example.com", "page b")
)
)
)
assertEquals(1, searchTaskDbService.statisticsInfo()["ok"])
val res = searchTaskDbService.getRecentTasks(0, 10)
assertEquals("ok", res.content[0].state)
val items = searchTaskDbService.getSearchResultItemsForTask(res.content[0].id!!)
assertEquals(2, items.size)
}
}
FetchTaskDbService 同理实现,略。此后,我们的消息队列服务和 web 服务只与这两个 DbService 交互,不会访问更低级的 Repository。
本章小结:
- Spring Data JDBC 能对简单查询生成 SQL,只需继承CrudRepository接口。它也支持分页查询,需要继承PagingAndSortingRepository接口。我们也可以自行编写 SQL。
- 要注意save方法的坑。必要时,自行编写插入和更新语句。
- 使用@Transactional将一系列数据库操作放进同一个事务。测试时也可以用@Transactional来保证测完后回滚。
消息队列服务
消息队列 Service 我们已经写过两遍了,这次也没有什么特殊之处。先写 Config 声明队列和 json 转换器,用单表达式函数简化代码:
@Configuration
class RabbitMQConfig {
@Bean
fun searchRequestQueue() = Queue("search_request", true)
@Bean
fun searchResponseQueue() = Queue("search_response", true)
@Bean
fun fetchRequestQueue() = Queue("fetch_request", true)
@Bean
fun fetchResponseQueue() = Queue("fetch_response", true)
@Bean
fun jsonMessageConverter() = Jackson2JsonMessageConverter()
}
实现 Search 和 Fetch 的 RabbitMQ Service:
@Service
class SearchRabbitService(
private val rabbitTemplate: RabbitTemplate,
private val searchTaskDbService: SearchTaskDbService
) {
private val log = LoggerFactory.getLogger(javaClass)
fun sendSearchRequest(message: SearchRequestMqDto) {
log.info("send: {}", message)
rabbitTemplate.convertAndSend("search_request", message)
}
@RabbitListener(queues = ["search_response"])
fun receive(message: SearchResultMqDto) {
log.info("recv: {}", message)
searchTaskDbService.updateTaskResult(message)
}
}
@Service
class FetchRabbitService(
private val rabbitTemplate: RabbitTemplate,
private val fetchTaskDbService: FetchTaskDbService
) {
private val log = LoggerFactory.getLogger(javaClass)
fun sendFetchRequest(message: FetchRequestMqDto) {
log.info("send: {}", message)
rabbitTemplate.convertAndSend("fetch_request", message)
}
@RabbitListener(queues = ["fetch_response"])
fun receive(message: FetchResultMqDto) {
log.info("recv: {}", message)
fetchTaskDbService.updateTaskResult(message)
}
}
对 RabbitListener 的集成测试有点难写,本文放弃。具体可以问 LLM。
web 服务
终于,本文来到了最后一节,我们开始接触一般被其他 Spring Boot 教程放在第一节的 web 服务。Spring 生态中有两种 web 服务:Spring Web MVC 和 Spring WebFlux,前者是传统的阻塞式 API,后者是响应式 API,且可以和 Kotlin 协程完美结合。尽管理论上说后者性能更好,但它与 Spring Data R2DBC 配合起来才能发挥全力;如果与本文已经选用的 Spring Data JDBC 配合,则 http handler 是异步的,占耗时大头的数据库访问反而是同步的,没有多少意义。所以本文选择传统 Spring Web MVC。
在 Restful API 后端服务中,我们会使用 @RestController。它的行为与 FastAPI 非常相似:接收一个请求对象,返回一个响应对象,而 json 序列化/反序列化由框架自动实现。我们来写个 ping handler:
@RestController
class PingController {
@GetMapping("/ping")
fun ping(name: String = "anonymous") = mapOf(
"serverStatus" to "fine",
"message" to "Hello, $name!",
)
}
访问 /ping?name=neko:
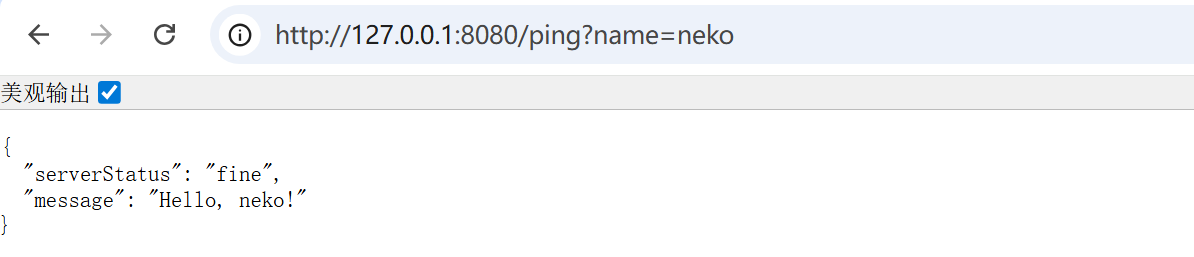
再写个 greeting handler:
// 在 PingController 中添加以下代码:
data class GreetingReq(val name: String, val location: String)
data class GreetingResp(val message: String, val cnt: Int)
private val counter = AtomicInteger(0)
@PostMapping("/greeting")
fun greeting(@RequestBody req: GreetingReq): GreetingResp {
return GreetingResp("Hello ${req.name}@${req.location}", counter.incrementAndGet())
}
往 /greeting 发 json:
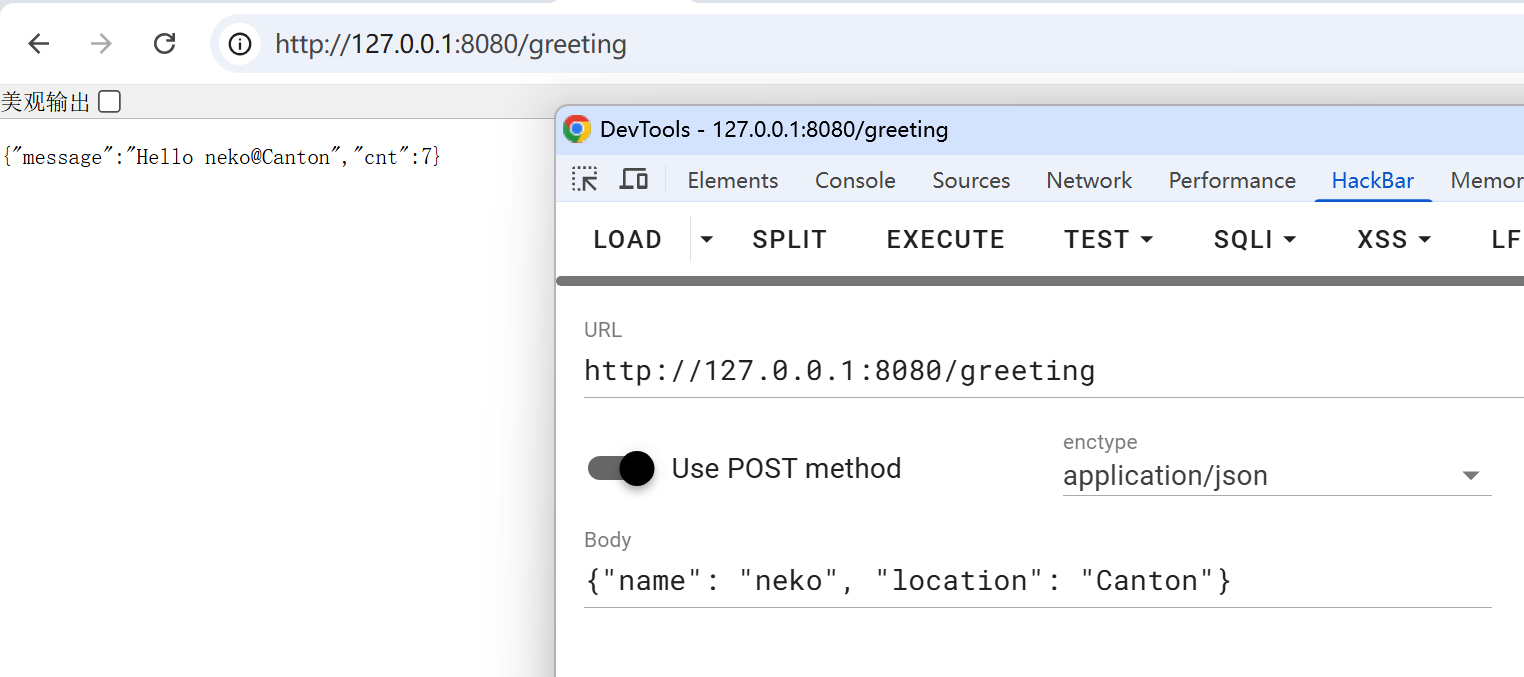
尝试一些非法数据(例如把 location 改成数组),会返回 400 Bad Request。这是类型系统带来的好处,我们可以把精力集中在业务逻辑上,而避免冗长的类型检查。这方面 Flask 明显做得不够好,它虽然返回对象是自动序列化的,但对 json POST 数据缺乏官方的反序列化方案,开发者需要自行使用 pydantic 等库。FastAPI 默认采用 pydantic 方案,但生态比起 Flask 有所欠缺。综合来看,Spring 是当代 Restful API 开发的较优选择。
另外,Flask、Gin、ktor、express 等框架中,想要建立一个 url 到 handler 的路由,一般需要显式地在根节点上注册之,例如 Flask 的 @app.route("/ping")、express 的 app.get("/ping", handler)。然而,在上面的 Spring MVC 代码中,handler 只有一个 @GetMapping("/ping") 注解,没有 app。换句话说,handler 是“声明自己该被映射到哪个路径”,而不是“由 app 显式地注册路由”。这又是“约定优于配置”的典例。
实现抓取 controller:
@RestController
@RequestMapping("/fetch-tasks")
class FetchController(
private val fetchTaskDbService: FetchTaskDbService,
private val fetchRabbitService: FetchRabbitService
) {
@GetMapping("/stats")
fun stats() = fetchTaskDbService.statisticsInfo()
@GetMapping("/{uuid}")
fun getOneTask(@PathVariable uuid: String) = fetchTaskDbService.getTask(uuid)
@GetMapping()
fun getTasks(page: Int = 0, size: Int = 50) = fetchTaskDbService.getRecentTasks(page, size)
data class NewTaskReq(
val url: String,
)
@PostMapping()
fun newTask(@RequestBody req: NewTaskReq): Map<String, String> {
val uuid = fetchTaskDbService.createNewTask(req.url)
fetchRabbitService.sendFetchRequest(FetchRequestMqDto(uuid, req.url))
return mapOf(
"uuid" to uuid
)
}
}
实现搜索 controller,由于需要把搜索出的结果组合进去,我们定义了 TaskVO 类,代码变得稍微复杂一些:
@RestController
@RequestMapping("/search-tasks")
class SearchController(
private val searchTaskDbService: SearchTaskDbService,
private val searchRabbitService: SearchRabbitService
) {
@GetMapping("/stats")
fun stats() = searchTaskDbService.statisticsInfo()
inner class TaskVO {
val id: Long
val mqId: String
val state: String
val keywords: String
val page: Int
val result: String?
val createdAt: Instant
val updatedAt: Instant?
val resultItems: List<SearchResultItem>
constructor(searchTask: SearchTask) {
id = searchTask.id!!
mqId = searchTask.mqId
state = searchTask.state
keywords = searchTask.keywords
page = searchTask.page
result = searchTask.result
createdAt = searchTask.createdAt!!
updatedAt = searchTask.updatedAt
resultItems = searchTaskDbService.getSearchResultItemsForTask(searchTask.id!!)
}
}
@GetMapping("/{uuid}")
fun getOneTask(@PathVariable uuid: String): TaskVO {
val taskEntity = searchTaskDbService.getTask(uuid)
return TaskVO(taskEntity)
}
@GetMapping()
fun getTasks(page: Int = 0, size: Int = 50): List<TaskVO> {
val taskEntities = searchTaskDbService.getRecentTasks(page, size)
return taskEntities.content.map { TaskVO(it) }
}
data class NewTaskReq(
val keywords: String,
val page: Int,
)
@PostMapping()
fun newTask(@RequestBody req: NewTaskReq): Map<String, String> {
val uuid = searchTaskDbService.createNewTask(req.keywords, req.page)
searchRabbitService.sendSearchRequest(SearchRequestMqDto(uuid, req.keywords, req.page))
return mapOf(
"uuid" to uuid
)
}
}
我们终于完全实现了爬虫控制中心。后续工作是用 Python 写个客户端,不过那已经超出本文的范畴了。
本章小结:
- 两种合理的组合:Spring Web MVC + Spring Data JDBC,或 Spring WebFlux + Spring Data R2DBC。
- 用@RestController标记 controller,用@GetMapping和@PostMapping等指定路由。
- 用@RequestBody标记输入对象。json 序列化/反序列化是自动进行的。
结语:本质复杂性与附属复杂性
《人月神话》在论述“没有银弹”时提出了一个观点:软件工程的复杂性可以分为本质复杂性和附属复杂性,前者的来源是业务本身的复杂性,业务本身的复杂性是无法减轻的;后者是为了实现业务而产生的复杂性,可以通过各种软件工程手段来解决。笔者举个例子:用户想要一个四则运算器,输入中缀表达式,输出计算结果。那我们会需要写个中缀表达式 parser,逻辑很复杂,但这是本质复杂性,几乎无法消减;另一方面,我们选用汇编来实现程序,与选用 Python 实现来程序,复杂性是不一样的,这就是附属复杂性,可以通过软件工程手段减少。
Java 本身很容易产生附属复杂性,一个最典型的例子就是 getter/setter。我们见惯了先声明 private xxx 变量然后定义 public setXxx() 和 public getXxx() 方法,这样的样板代码充斥于古代 Java 程序中。Project Lombok 和 Java 14+ 的 record 可以缓解这一问题,而 Kotlin 可以说是彻底解决了这个问题。另一个例子是,在古代 Java 中,如果我们有一个字符串列表 a,现在想给其中每个元素转成 int 并求平方,那我们会需要先创建一个 result 列表,然后遍历字符串列表,对每个 a[i] 执行 parseInt 和平方,把结果加入 result 列表。 JDK 8 引入了 stream API 和 lambda 表达式,让我们可以用 a.stream().map(Integer::parseInt).map(n -> n * n).collect(Collectors.toList()),比旧方案优雅很多,减少了一部分附属复杂性。而在 Kotlin 中,一句 a.map{ it.toInt() }.map { it * it } 足矣。Kotlin 的设计哲学就是清理掉 Java 在语法层面的附属复杂性。
从“本质复杂性 vs 附属复杂性”这个理论框架来看,Spring 也是“减少附属复杂性”的杰作。Java 不提供原生的单例,它就维护一个 Bean 单例仓库,开发者想要哪个单例就有哪个单例,而无需手动管理单例的生命周期(例如,我该选择懒汉式还是饿汉式……);@RequestBody 让开发者从“手动把 json 反序列化为 Map、验证各个字段的合法性”中解脱出来,开发者拿到的数据一定是格式合法的;如果使用原生 RabbitMQ API,我们需要与 worker 池打交道,但 Spring AMQP 接管了这一切,我们只需要用 rabbitTemplate.convertAndSend 发消息,用 @RabbitListener 监听消息;对于数据库地址,我们有默认值,但也允许环境变量覆盖默认值,还要允许命令行参数覆盖环境变量,按理来说我们该手写相关代码,但用上 Spring 的 @Value 之后,默认就支持这些设置方法,默认就是这样的优先级。Spring 极大程度上缓解了业务代码中的附属复杂性,自动处理各种杂活,让开发者专注于主要的业务逻辑。
软件工程发展的历史,就是不断减少附属复杂性、让开发者专心处理主要复杂性的历史。从这方面看,Spring Boot 无疑是 Java 生态中的里程碑。笔者初学 Spring,水平有限,本文也是挂一漏万,但希望读者能从本文中多少感受到一点 Spring 的设计哲学。