
前置
截至写本文时,洛谷已经积攒了3100余万次提交。本文用Python爬取了一些提交的样本,以供后续数据分析。
爬取页面
洛谷第x个提交记录,URL是https://www.luogu.com.cn/record/{id},但使用 requests 库直接GET请求时,返回错误。原因是需要先登录。故从chrome中得到 user-agent 和 cookie, 伪造成chrome来发出访问。

url = f'https://www.luogu.com.cn/record/{id}'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
'cookie': '**********************'
}
print(url)
r = rq.get(url, headers=headers, timeout = 5)
获取数据
之前通过GET请求,得到的网页为:
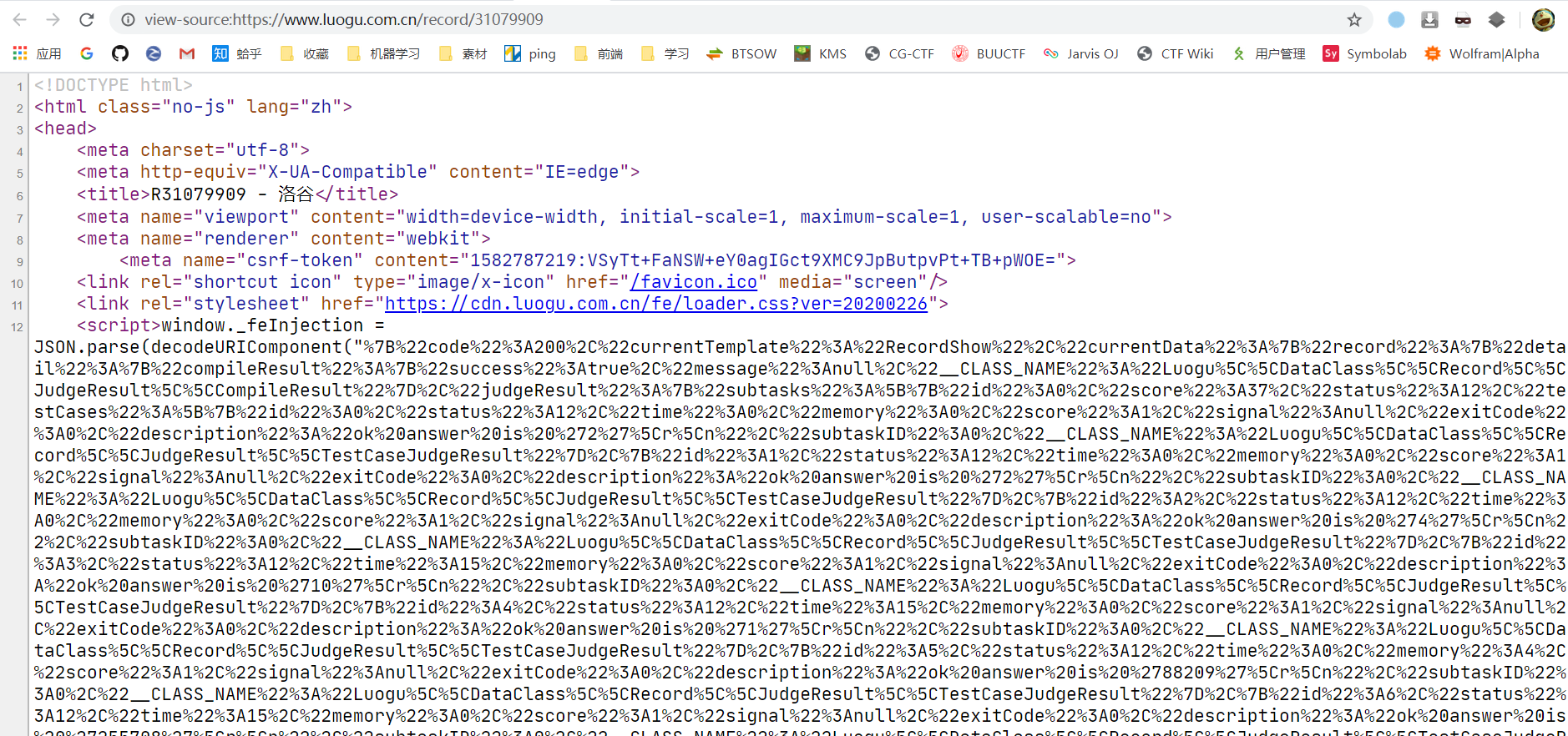
洛谷采用了严格的前后端分离来开发网站,这对我们的爬虫非常有帮助。
接下来,我们只需要取得那一大段js里面返回的数据。这里采用beautifulsoup,代码如下:
soup = BeautifulSoup(r.text, 'html.parser')
res = soup.script.get_text()
res = unquote(res.split('\"')[1])
data = json.loads(res)
data = data['currentData']['record']
于是 res 即为script中双引号内的代码,即为我们想要爬取的数据。它是一个json格式,因此用 json.loads() 来得到一个dict,里面包含着所需的信息。
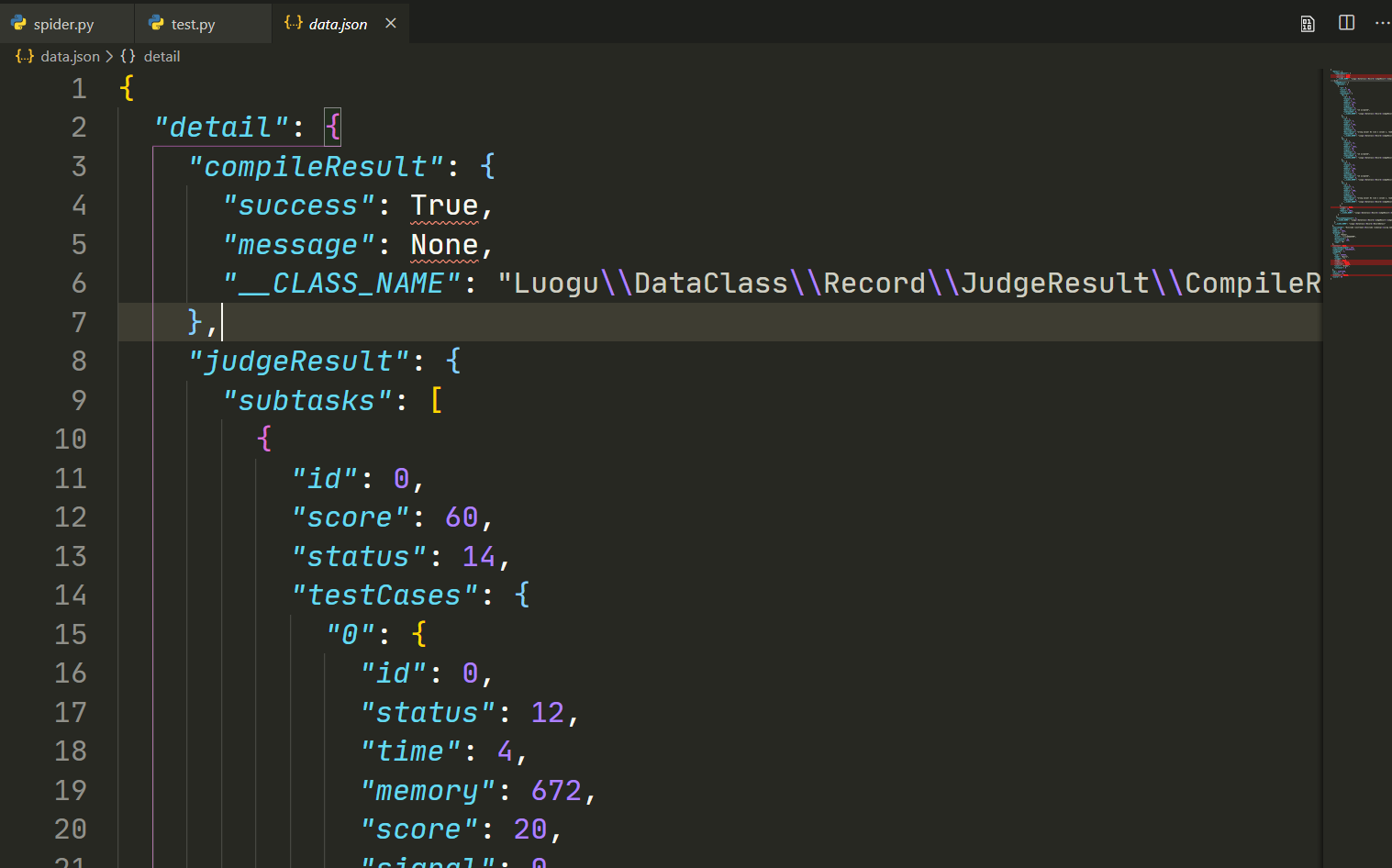
储存数据
这一次我们采用MongoDB. 初始化如下:
myclient = pymongo.MongoClient("mongodb://********:27017/")
mydb = myclient['luogu']
mycol = mydb['records']
MongoDB的服务端是利用docker部署的,非常简单,只需要暴露一个端口出去即可。
存储数据也异常简单:
if list(mycol.find({'id' : id})) == []:
mycol.insert_one(data)
else:
print("Already")
要读取数据,只需
print(list(mycol.find()))
多线程爬取
采用threading库来进行多线程爬取网页。
每个worker负责爬取100个网页;共100个worker参与工作。
def worker(x):
print(f'worker {x} start')
for i in range(x, x+100):
try:
getRecord(i)
except Exception:
pass
print(f'worker {x} stop')
if __name__ == '__main__':
pool = [threading.Thread(target=worker, args=[31000000 + x*100]) for x in range(100)]
for x in pool:
x.start()
for x in pool:
x.join()
至此爬虫完成,还把洛谷给爬崩了(划掉)。

最终代码
import requests as rq
from urllib.parse import unquote
from bs4 import BeautifulSoup
from re import findall
import json
import pymongo
import threading
myclient = pymongo.MongoClient("mongodb://*******:27017/")
mydb = myclient['luogu']
mycol = mydb['records']
def getRecord(id):
url = f'https://www.luogu.com.cn/record/{id}'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
'cookie': '**********'
}
print(url)
r = rq.get(url, headers=headers, timeout = 5)
soup = BeautifulSoup(r.text, 'html.parser')
res = soup.script.get_text()
res = unquote(res.split('\"')[1])
data = json.loads(res)
data = data['currentData']['record']
# print(data)
if list(mycol.find({'id' : id})) == []:
mycol.insert_one(data)
else:
print("Already")
def worker(x):
print(f'worker {x} start')
for i in range(x, x+100):
try:
getRecord(i)
except Exception:
pass
print(f'worker {x} stop')
if __name__ == '__main__':
pool = [threading.Thread(target=worker, args=[31000000 + x*100]) for x in range(100)]
for x in pool:
x.start()
for x in pool:
x.join()