
Exercise1: Xpdf
这个练习要求我们 fuzz 出 Xpdf CVE-2019-13288 漏洞。攻击者可以使程序陷入无限递归,从而达到 DoS 目的。
0x01 准备工作
首先编译 xpdf:
wget https://dl.xpdfreader.com/old/xpdf-3.02.tar.gz
tar -zxvf xpdf-3.02.tar.gz
cd xpdf-3.02/
CC=/afl/afl-clang-lto CXX=/afl/afl-clang-lto++ ./configure --prefix="/home/xpdf/out"
# ...
# configure: WARNING: -- You will be able to compile pdftops, pdftotext,
# pdfinfo, pdffonts, and pdfimages, but not xpdf or pdftoppm
make
# strcmp: length 3/3 "def"
# AUTODICTIONARY: 309 strings found
# [+] Instrumented 20658 locations (1357 selects) without collisions (2939 collisions have been avoided) (non-hardened mode).
# make[1]: 离开目录“/home/xpdf/xpdf-3.02/xpdf”
make install
编译完成,程序可以跑起来了:
弄来一些测试用例:
wget https://github.com/mozilla/pdf.js-sample-files/raw/master/helloworld.pdf
wget http://www.africau.edu/images/default/sample.pdf
wget https://www.melbpc.org.au/wp-content/uploads/2017/10/small-example-pdf-file.pdf
0x02 fuzz
我们的 fuzz 目标是 pdftotext 程序。这个程序负责从 pdf 中提取文本:
执行 fuzz(这里的指令和教程不一样,笔者把程序输出放到了 stdout):
/afl/afl-fuzz -i inputs/ -o out -s 123 -- ./pdftotext @@ -五分多钟之后,出现几个 crash:
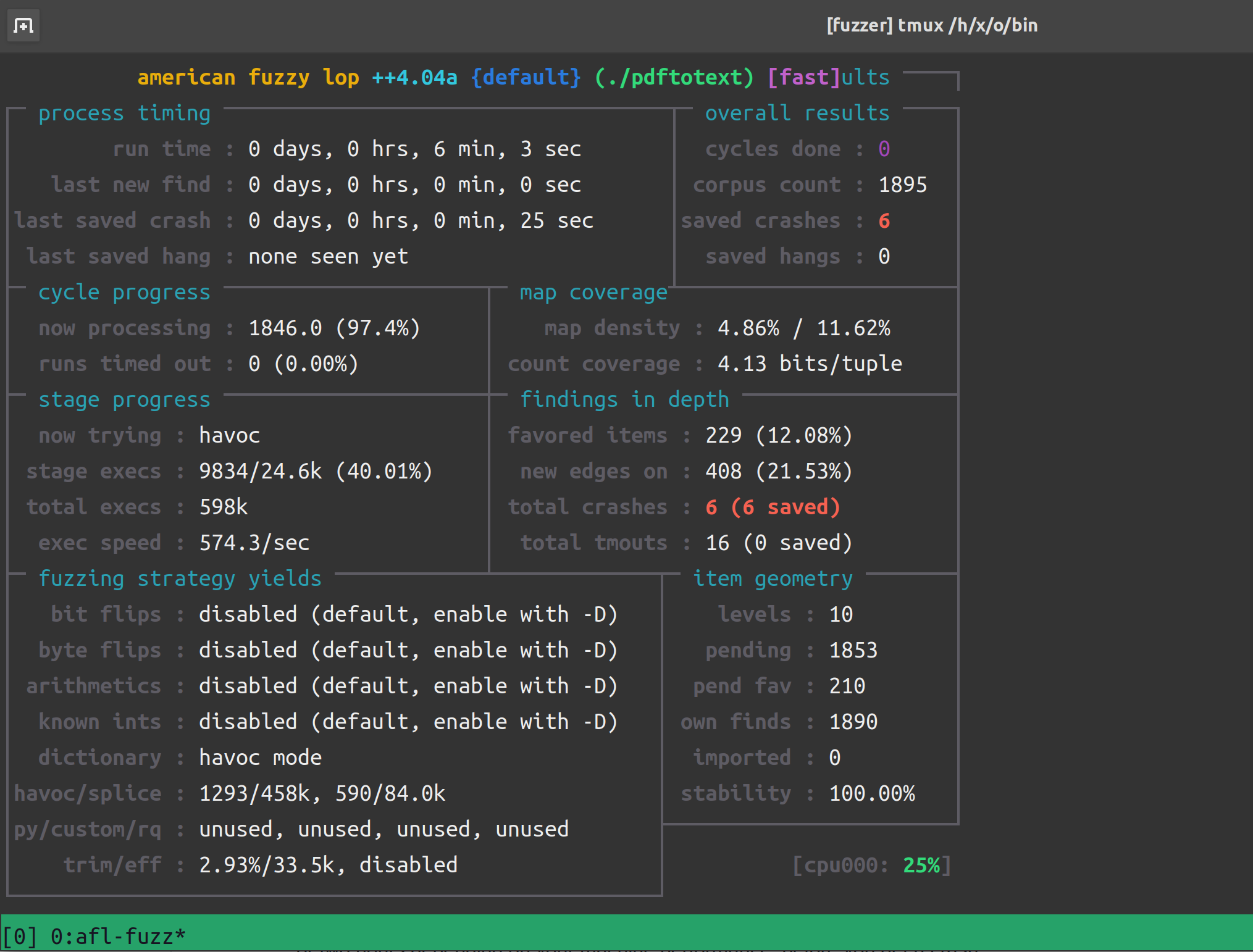
再跑一会:
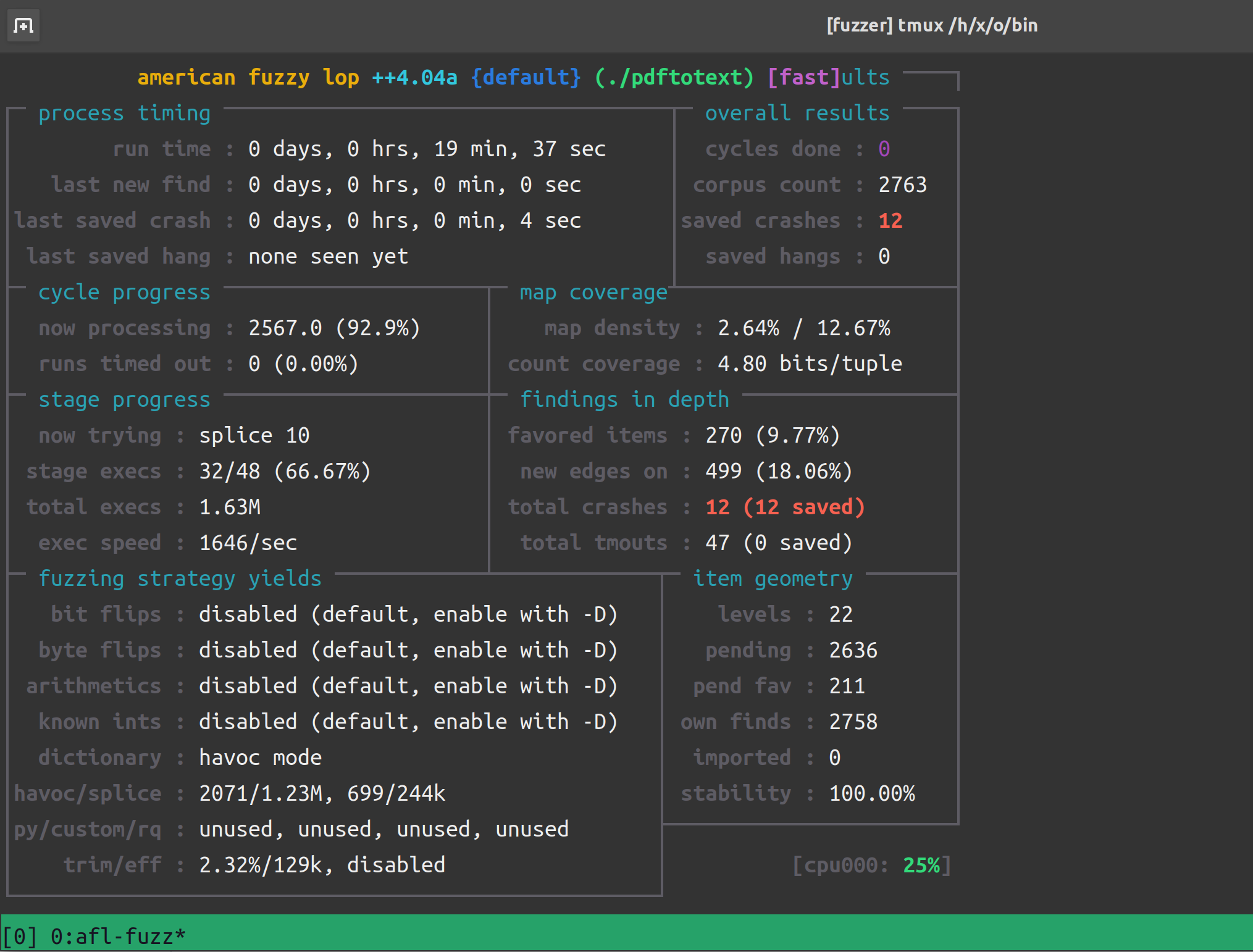
我们的 fuzzing 效率比 Fuzzing101 教程文档快不少,几乎是一倍的速度。来看一下 crash 输入:
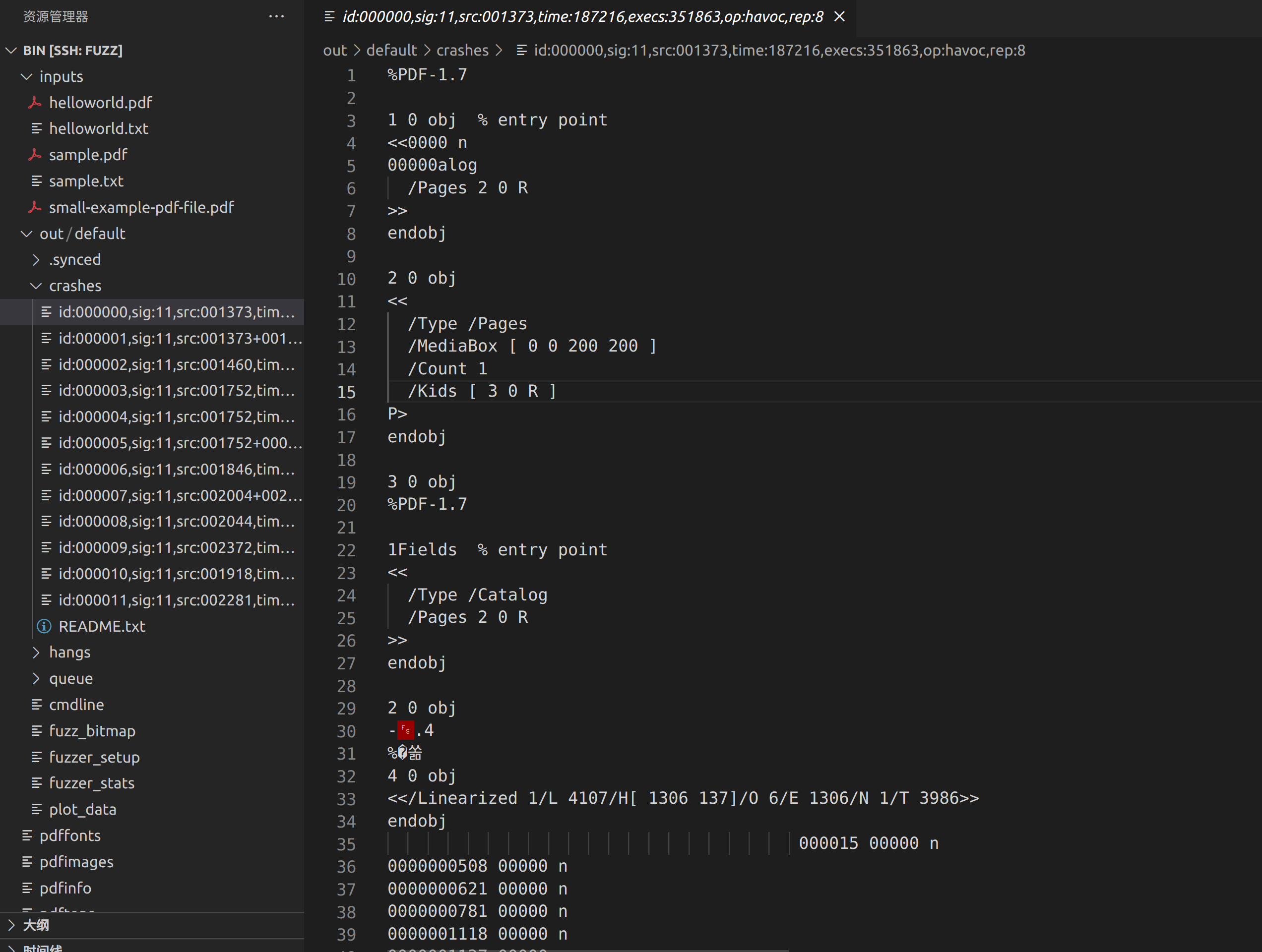
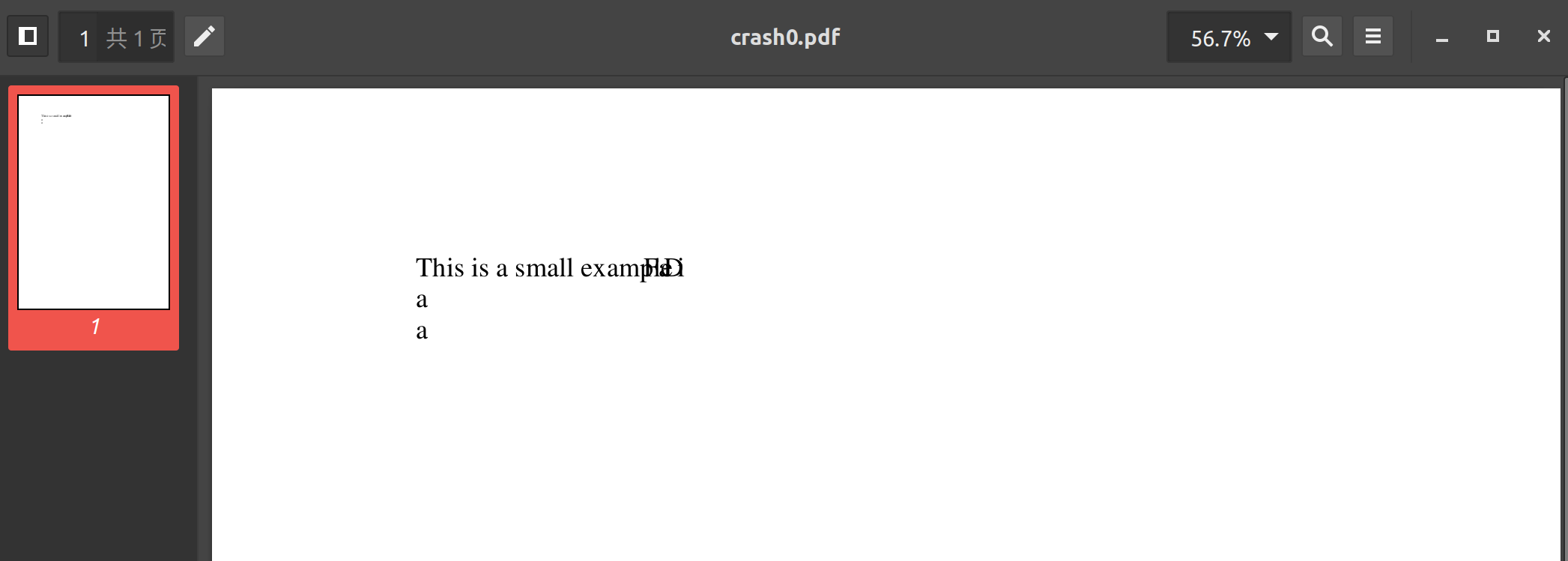
测试一下:

复现 segmentation fault。接下来,我们尝试分析这个漏洞。
0x03 漏洞分析
拿 lldb 去调试。首先用 crash 输入让它崩溃,然后看看 stack 现场:thread backtrace unique
这相当明显是无限递归了。用 VS Code 调试,先看看这个环的入口:
因此这一个 Object::fetch(XRef*, Object*) 应该是入口。先看看程序从 main 到这个位置的过程。
VS Code 提示 main 执行 info.isDict() 时调用了 displayPages(),然而事实上这个 isDict() 如下:
class Object {
public:
// Default constructor.
Object():
type(objNone) {}
// ...
GBool isArray() { return type == objArray; }
GBool isDict() { return type == objDict; }
GBool isStream() { return type == objStream; }
GBool isRef() { return type == objRef; }
// ... 这显然不可能调用 displayPages(),分析过程出错了。想到可能 -O2 选项对 debug 有影响,我们用 -O0 重新编译一遍:
./configure --prefix="/home/blue/Desktop/workspace/xpdf" CFLAGS="-O0 -g" CXXFLAGS="-O0 -g" CC=afl-clang-lto CXX=afl-clang-lto++
make 于是在 main() 中指示了正确的位置。
这段代码的逻辑是:准备一个输出设备(本例中是 stdout),就绪后调用 doc->displayPages() 输出文本。跟进 displayPages :
void PDFDoc::displayPages(OutputDev *out, int firstPage, int lastPage,
double hDPI, double vDPI, int rotate,
GBool useMediaBox, GBool crop, GBool printing,
GBool (*abortCheckCbk)(void *data),
void *abortCheckCbkData) {
int page;
for (page = firstPage; page <= lastPage; ++page) {
displayPage(out, page, hDPI, vDPI, rotate, useMediaBox, crop, printing,
abortCheckCbk, abortCheckCbkData);
}
} 也就是对于 pdf 中的每一页,调用 displayPage 将其转文字输出。跟进 displayPage :
void PDFDoc::displayPage(OutputDev *out, int page,
double hDPI, double vDPI, int rotate,
GBool useMediaBox, GBool crop, GBool printing,
GBool (*abortCheckCbk)(void *data),
void *abortCheckCbkData) {
if (globalParams->getPrintCommands()) {
printf("***** page %d *****\n", page);
}
catalog->getPage(page)->display(out, hDPI, vDPI,
rotate, useMediaBox, crop, printing, catalog,
abortCheckCbk, abortCheckCbkData);
} 通过 catalog->getPage(page) 来获取指定页码,再将其展示出来。由于我们 pdf 只有一页,这个 getPage 结果肯定是第一页。跟进 Page::display:
void Page::display(OutputDev *out, double hDPI, double vDPI,
int rotate, GBool useMediaBox, GBool crop,
GBool printing, Catalog *catalog,
GBool (*abortCheckCbk)(void *data),
void *abortCheckCbkData) {
displaySlice(out, hDPI, vDPI, rotate, useMediaBox, crop,
-1, -1, -1, -1, printing, catalog,
abortCheckCbk, abortCheckCbkData);
} 是直接调用 displaySlice 输出。跟进:
void Page::displaySlice(OutputDev *out, double hDPI, double vDPI,
int rotate, GBool useMediaBox, GBool crop,
int sliceX, int sliceY, int sliceW, int sliceH,
GBool printing, Catalog *catalog,
GBool (*abortCheckCbk)(void *data),
void *abortCheckCbkData) {
#ifndef PDF_PARSER_ONLY
PDFRectangle *mediaBox, *cropBox;
PDFRectangle box;
Gfx *gfx;
Object obj;
Annots *annotList;
Dict *acroForm;
int i;
if (!out->checkPageSlice(this, hDPI, vDPI, rotate, useMediaBox, crop,
sliceX, sliceY, sliceW, sliceH,
printing, catalog,
abortCheckCbk, abortCheckCbkData)) {
return;
}
rotate += getRotate();
if (rotate >= 360) {
rotate -= 360;
} else if (rotate < 0) {
rotate += 360;
}
makeBox(hDPI, vDPI, rotate, useMediaBox, out->upsideDown(),
sliceX, sliceY, sliceW, sliceH, &box, &crop);
cropBox = getCropBox();
if (globalParams->getPrintCommands()) {
mediaBox = getMediaBox();
printf("***** MediaBox = ll:%g,%g ur:%g,%g\n",
mediaBox->x1, mediaBox->y1, mediaBox->x2, mediaBox->y2);
printf("***** CropBox = ll:%g,%g ur:%g,%g\n",
cropBox->x1, cropBox->y1, cropBox->x2, cropBox->y2);
printf("***** Rotate = %d\n", attrs->getRotate());
}
gfx = new Gfx(xref, out, num, attrs->getResourceDict(),
hDPI, vDPI, &box, crop ? cropBox : (PDFRectangle *)NULL,
rotate, abortCheckCbk, abortCheckCbkData);
contents.fetch(xref, &obj);
// 在这个 fetch() 内进入无限递归
if (!obj.isNull()) {
gfx->saveState();
gfx->display(&obj);
gfx->restoreState();
}
obj.free();
// draw annotations
annotList = new Annots(xref, catalog, getAnnots(&obj));
obj.free();
acroForm = catalog->getAcroForm()->isDict() ?
catalog->getAcroForm()->getDict() : NULL;
if (acroForm) {
if (acroForm->lookup("NeedAppearances", &obj)) {
if (obj.isBool() && obj.getBool()) {
annotList->generateAppearances(acroForm);
}
}
obj.free();
}
if (annotList->getNumAnnots() > 0) {
if (globalParams->getPrintCommands()) {
printf("***** Annotations\n");
}
for (i = 0; i < annotList->getNumAnnots(); ++i) {
annotList->getAnnot(i)->draw(gfx, printing);
}
out->dump();
}
delete annotList;
delete gfx;
#endif
} 我们是在执行 contents.fetch(xref, &obj) 时陷入无限递归。 contents 是一个 Object,type 为 objRef,里面有一个 union, Ref 二元组为 (num=7, gen=0)。 来研究一下 xref,它是 Page 类里面的成员,定义:
class Page {
private:
XRef *xref; // the xref table for this PDF file
int num; // page number
PageAttrs *attrs; // page attributes
Object annots; // annotations array
Object contents; // page contents
GBool ok; // true if page is valid
} 注释里面表示 xref 是 pdf 文件的 xref table。查阅资料:

简而言之,xref table 是文件里所有 object 的索引表。编码规则如下:
来看看示例文件 helloworld.pdf 的 xref 表:
另一篇资料中提到,xref table 的目的是允许随机访问文件中的 object 而无需先读入整个 pdf。那么,当 xref 表损坏时,我们应当可以从文件中重构 xref 表。
分析 crash 输入,有的 input 不存在 xref table(但有 startxref 字符串),有的 xref table 损坏。xref table 损坏的例子:
动态调试后发现,“xref 损坏”与“xref 不存在”的例子,崩溃路径并不相同。所以我们还是继续分析原来的 xref 不存在的例子。
在这里,xref 仅有一个 entry,其 offset 为 4294967295,明显不合理。跟进这个 contents.fetch():
Object *Object::fetch(XRef *xref, Object *obj) {
return (type == objRef && xref) ?
xref->fetch(ref.num, ref.gen, obj) : copy(obj);
} 就是包装了一下 xref 对象自己的 fetch(),其中由于 contents 共用体里面 ref.num=7, ref.gen=0,所以这里调用的是 xref->fetch(7, 0, &obj)。现在我们去跟进 XRef::fetch:
Object *XRef::fetch(int num, int gen, Object *obj) {
XRefEntry *e;
Parser *parser;
Object obj1, obj2, obj3;
// check for bogus ref - this can happen in corrupted PDF files
if (num < 0 || num >= size) {
goto err;
}
e = &entries[num];
switch (e->type) {
case xrefEntryUncompressed:
if (e->gen != gen) {
goto err;
}
obj1.initNull();
parser = new Parser(this,
new Lexer(this,
str->makeSubStream(start + e->offset, gFalse, 0, &obj1)),
gTrue);
parser->getObj(&obj1);
parser->getObj(&obj2);
parser->getObj(&obj3);
if (!obj1.isInt() || obj1.getInt() != num ||
!obj2.isInt() || obj2.getInt() != gen ||
!obj3.isCmd("obj")) {
obj1.free();
obj2.free();
obj3.free();
delete parser;
goto err;
}
parser->getObj(obj, encrypted ? fileKey : (Guchar *)NULL,
encAlgorithm, keyLength, num, gen);
obj1.free();
obj2.free();
obj3.free();
delete parser;
break;
case xrefEntryCompressed:
// ...
break;
default:
goto err;
}
return obj;
err:
return obj->initNull();
} 其中,这一句 parser->getObj(obj, encrypted ? fileKey : (Guchar *)NULL, encAlgorithm, keyLength, num, gen) 进入死递归。动态调试到这里,它的实际参数是: getObj(obj, NULL, <RC4>, 0, 7, 0)。推测语义为把 obj 置为 id=7 的 object。跟进 getObj:
Object *Parser::getObj(Object *obj, Guchar *fileKey,
CryptAlgorithm encAlgorithm, int keyLength,
int objNum, int objGen) {
// ...
// array
if (buf1.isCmd("[")) {
// ...
// dictionary or stream
} else if (buf1.isCmd("<<")) {
shift();
obj->initDict(xref); // 初始化 obj 为 objDict
while (!buf1.isCmd(">>") && !buf1.isEOF()) {
if (!buf1.isName()) {
error(getPos(), "Dictionary key must be a name object");
shift();
} else {
key = copyString(buf1.getName());
shift();
if (buf1.isEOF() || buf1.isError()) {
gfree(key);
break;
}
obj->dictAdd(key, getObj(&obj2, fileKey, encAlgorithm, keyLength,
objNum, objGen));
}
}
if (buf1.isEOF())
error(getPos(), "End of file inside dictionary");
// stream objects are not allowed inside content streams or
// object streams
if (allowStreams && buf2.isCmd("stream")) {
if ((str = makeStream(obj, fileKey, encAlgorithm, keyLength,
objNum, objGen))) {
// 这个 makeStrem 进入无限递归
// ... 这里调用 Parser::makeStream,参数列表与上文的 getObj 参数基本相同。跟进:
Stream *Parser::makeStream(Object *dict, Guchar *fileKey,
CryptAlgorithm encAlgorithm, int keyLength,
int objNum, int objGen) {
Object obj;
BaseStream *baseStr;
Stream *str;
Guint pos, endPos, length;
// get stream start position
lexer->skipToNextLine();
pos = lexer->getPos();
// get length
dict->dictLookup("Length", &obj);
// 在此处进入无限递归
if (obj.isInt()) {
length = (Guint)obj.getInt();
obj.free();
} else {
error(getPos(), "Bad 'Length' attribute in stream");
obj.free();
return NULL;
}
// ... 这里的 dict 就是我们传进来的 obj,即 Page 类所调用的 contents.fetch(xref, &obj) 里面的 obj。它现在已经被组装成一个 objDict,顾名思义应该是一个 dictionary。那么猜测这一行 dict->dictLookup("Length", &obj) 的语义是“从 dict 中查找键 Length 对应的 value”。跟进:
inline Object *Object::dictLookup(char *key, Object *obj)
{ return dict->lookup(key, obj); } 应当注意上面代码中的 dict 是这个 Object 的 private 成员(类型为 Dict ),而非这个名为 dict 的 Object 本身。如下图,dictionary 里面存在名为 Length 的键。
跟进这个 lookup:
Object *Dict::lookup(char *key, Object *obj) {
DictEntry *e;
return (e = find(key)) ? e->val.fetch(xref, obj) : obj->initNull();
} 这里 find(key) 是寻找到 dictionary 里面的一条 entry,寻找成功之后,调用 e->val.fetch(xref, obj)。动态调试知,这里的 e->val 是一条 objRef:
发现这个 objRef 的 ref 属性是二元组 (num=7, gen=0),与 contents 一致。跟进这个 (e->val).fetch。
Object *Object::fetch(XRef *xref, Object *obj) {
return (type == objRef && xref) ?
xref->fetch(ref.num, ref.gen, obj) : copy(obj);
} 实际调用的是 xref->fetch(7, 0, &newobj),而我们之前讨论过 contents.fetch(xref, &obj) 触发的 xref->fetch(7, 0, &obj),至此,我们成功还原了递归链条:
main经过一些过程之后,调用displaySlice输出一些文本displaySlice调用contents.fetch(xref, &obj),其中contents是一个objRef,共用体ref二元组为(num=7, gen=0)xref->fetch(ref.num, ref.gen, obj)被调用,实际上 call 了xref->fetch(7, 0, obj)xref->fetch过程中,检测到这条 entry 是未被压缩的,调用parser->getObj(obj, fileKey=NULL, encAlgorithm=<RC4>, keyLength0, num=7, gen=0),以获取 num=7, gen=0 这个 pdf objectParser::getObj过程中,首先通过obj->initDict(xref)把obj从objNone初始化成一个objDict,调用makeStream(obj, fileKey=NULL, encAlgorithm=<RC4>, keyLength=0, objNum=7, objGen=0)生成一个StreamParser::makeStream过程中,调用obj->dictLookup("Length", &newobj),意图是从现在已经是objDict的obj里面取 key 为"Length"的键值对,把 value 给newobj- 上述
dictLookup是一个简单封装,调用obj->dict->lookup("Length", &newobj) - 上述
lookup从obj->dict这个 dictionary 里面寻找到 key 为"Length"的 entrye: (key="Length", val=<objRef>),且这里的这个类型为objRef的val的ref二元组为(num=7, gen=0)。调用val.fetch(xref, &newobj) - 上述
val.fetch(xref, &newobj),由于val的ref二元组为(num=7, gen=0),所以会调用xref->fetch(7, 0, &newobj),这个 call 与第 3 条分析的 call 作用相同,至此进入无限递归。
上述过程中,最违背常理的是第 6 条,Length 这个键为什么会对应一个 objRef 而不是 objInt。我们再看一遍 makeStream 过程:
// get length
dict->dictLookup("Length", &obj); // 在这里陷入无限递归
if (obj.isInt()) {
length = (Guint)obj.getInt();
obj.free();
} else {
error(getPos(), "Bad 'Length' attribute in stream");
obj.free();
return NULL;
} 这说明开发者也期望 Length 键对应一个整数,如果不是整数的话会报错。可惜程序没等到运行至 isInt() 检测,就进入死递归了。
正常的运行逻辑应该是: Length 键对应一个 objInt 类型的 val,调用 val.fetch(xref, &newobj) :
Object *Object::fetch(XRef *xref, Object *obj) {
return (type == objRef && xref) ?
xref->fetch(ref.num, ref.gen, obj) : copy(obj);
} 如果 val 是 objInt 类型,那么它将会返回自己这个 objInt 的副本。程序将会正常运行,而不是递归 fetch 下去。
0x04 修复
在研究清楚为什么 crash 之后,我们的修复方案已经明了:若 Length 所对应的 val 不是 objInt,则不能执行第 6 条分析里的 obj->dictLookup("Length", &newobj) 。这可以通过在各种入口处特判来实现,但考虑到 lookup 使用非常频繁,入口处判断容易影响性能;且如果我们在 lookup 前就终止程序,那么原有的 makeStream 中判断 val 是否合法的代码就不能复用。故笔者写了 Length 查询特制版的 Dict::lookupLength 和 Object::dictLookupLength:
Object *Dict::lookupLength(char *key, Object *obj) {
DictEntry *e;
return (e = find(key)) ? e->val.copy(obj) : obj->initNull();
}
inline Object *Object::dictLookupLength(char *key, Object *obj)
{ return dict->lookupLength(key, obj); } 并将 Parser::makeStream 里的代码做如下修改。这样 patch 不影响程序性能。
// get length
[-] dict->dictLookup("Length", &obj);
[+] dict->dictLookupLength("Length", &obj);完整的改动列表可以在 git diff 中查看:https://github.com/Ruanxingzhi/Fuzzing101/commit/57d3...
正常功能测试:
crash0 测试:
crash1 测试:
可见我们成功修复了 bug。至此,我们完成了 exercise 1 的 fuzzing、复现和修复。
0x05 总结
-O2可能影响调试。调试时应该采用-O0。- 复现漏洞需要一些耐心。